Компания NVIDIA начала год с анонса нового поколения видеокарт GeForce RTX 50-й серии на архитектуре Blackwell. Старшие модели GeForce RTX 5090 и GeForce RTX 5080 уже поступили в продажу, сегодня к ним присоединится GeForce RTX 5070 Ti, а в марте на рынок выйдет GeForce RTX 5070. Данное поколение уже вызвало определенные споры. С одной стороны — много новых революционных технологий, DLSS 4 с улучшенным масштабированием и генерацией до трех дополнительных кадров; с другой стороны — высокое энергопотребление, высокие цены и небольшое преимущество в обычных играх с растеризацией. Действительно, новая серия GeForce оказалось прорывной не во всем. Закон Мура сейчас серьезно замедлился, эволюция за счет освоения новых техпроцессов уже не работает, невозможно постоянно наращивать количество транзисторов и получать быстрые холодные видеокарты. И хотя инженеры NVIDIA постарались достичь лучшей энергоэффективности в новом поколении, главное преимущество архитектуры NVIDIA Blackwell в оптимизациях для нейронных нагрузок и тех перспективах, что она открывает для дальнейшего развития графики в играх.

Главные особенности архитектуры NVIDIA Blackwell
- Новые функции в SM и вычислительных ядрах для нейронных шейдеров, в том числе удвоение пропускной способности целочисленных вычислений за такт
- Новые функции Max-Q для лучшей энергоэффективности и более тонкого управления питанием разных блоков GPU
- Новые ядра RT 4-го поколения для трассировки лучей и нейронного рендеринга
- Новые тензорные ядра 5-го поколения с повышенной производительностью и поддержкой новых типов вычислений FP4
- Новая технология DLSS 4 с многокадровой генерацией
- Нейронные шейдеры — новый тип шейдеров, который открывает новую эру графических инноваций
- AI Management Processor — дополнительный сопроцессор для управления задачами ИИ
- Новая скоростная память GDDR7 с высокой пропускной способностью
- Технология RTX Mega Geometry направленная на увеличение геометрии в сценах с трассировкой лучей
Все видеокарты получили обновленные блоки кодирования/декодирования видео. Улучшен механизм управления Boost. Также новое поколение поддерживает интерфейс PCI Express 5.0. Обо всем этом мы расскажем ниже.

На данный момент анонсировано четыре видеокарты — GeForce RTX 5090, RTX 5080, RTX 5070 Ti и RTX 5070.
Архитектура NVIDIA Blackwell и GPU GB202
Новая архитектура получила название в честь американского математика Дэвида Гарольда Блэквелла, известного работами в области математической статистики. Рассмотрим основные архитектурные изменения на примере старшего графического процессора GB202, который лег в основу флагмана GeForce RTX 5090. Это очень большой и сложный чип, который насчитывает 92 миллиарда транзисторов. Изготовляется он на заводах TSMC по техпроцессу 4N, который является специальной оптимизированной версией технологии 5 нм. На этом же техпроцессе выпускалось и прошлое поколение GPU Ada Lovelace для GeForce RTX 40. При этом плотность транзисторов у нового GPU составляет 122,9 миллиона на кв. мм, а у предшественника 125,3 миллиона на кв. мм.
Общая структура GB202 напоминает прошлый чип AD102. Это 12 кластеров GPC, один из которых у GeForce RTX 5090 деактивирован. Традиционно процессор идет с частично отключенными блоками, что позволяет использовать кристаллы с небольшими дефектами и повышает общий процент пригодных к использованию чипов. На уровне глобального управления потоками кроме GigaThread Engine появился AI Management Processor. Также у графического процессора есть Optical Flow Engine, который внедрили в прошлом поколении.
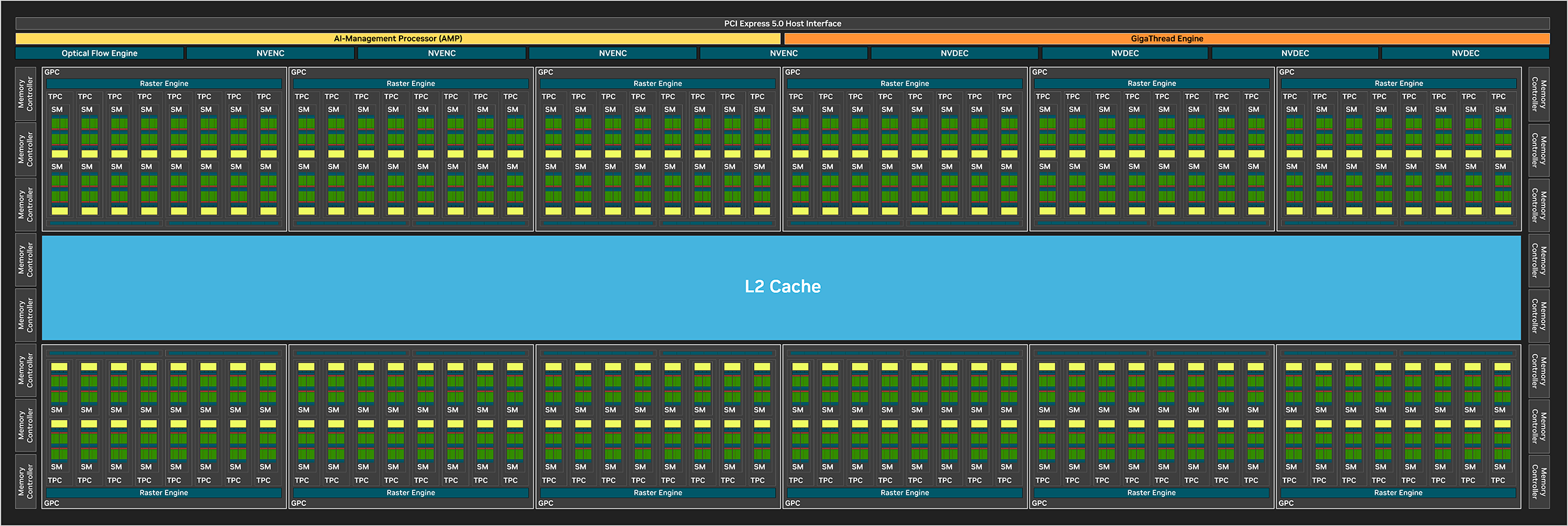
Кластер GPC является основным высокоуровневым блоком во всех графических процессорах NVIDIA. Внутри одного кластера 8 блоков TPC и разделенный на два раздела движок растеризации по 8 блоков ROP в каждом. Каждый TPC содержит два мультипроцессора SM с основными вычислительными ядрами и PolyMorph Engine.
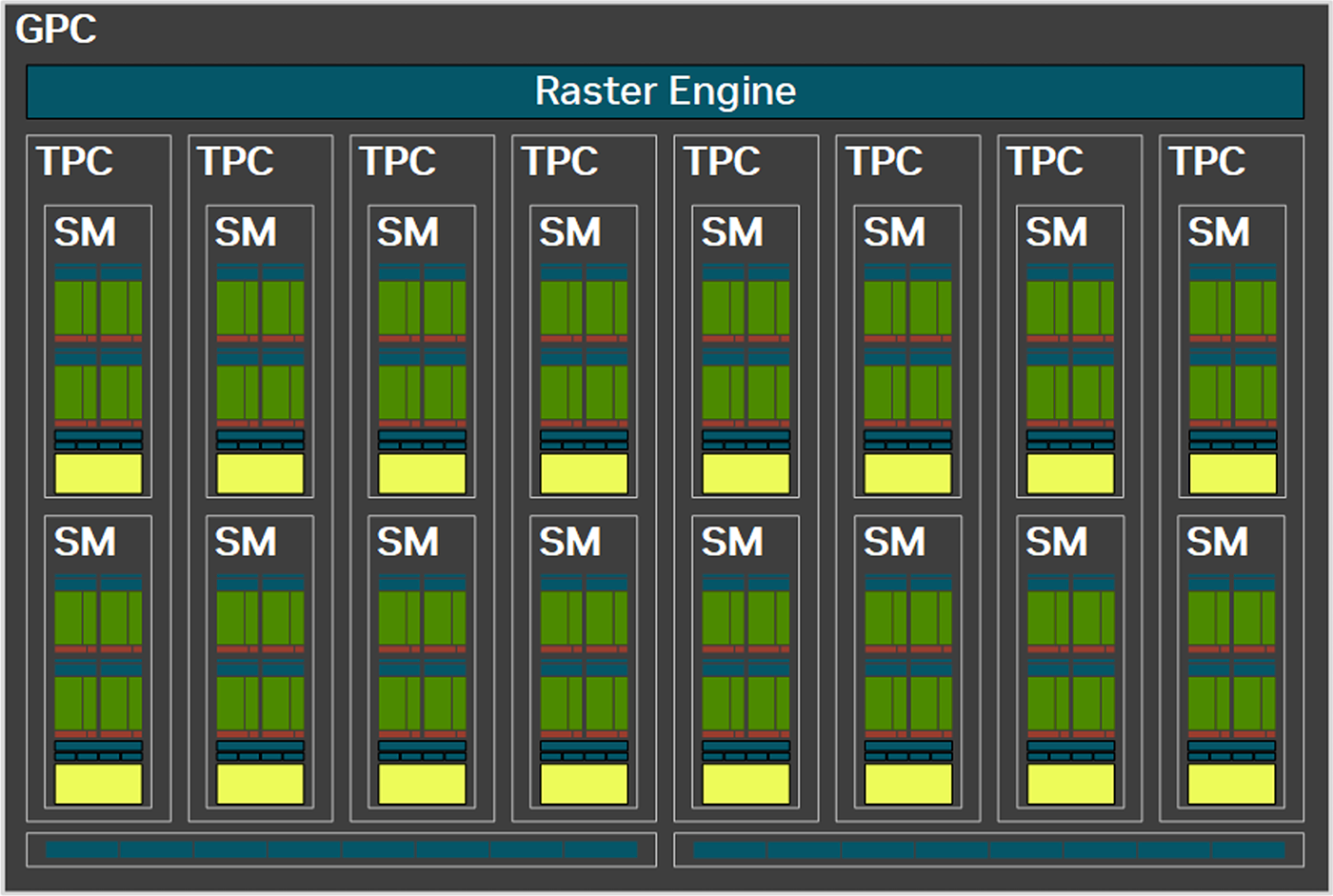
SM является главным компонентом архитектуры, играя основную роль в параллельной обработке. Каждый SM содержит 128 ядер CUDA, которые организованы в четыре группы со своими текстурными блоками, тензорными блоками и регистрами, плюс кэш L1 и планировщик с диспетчером потоков у каждой из 4 групп. Каждый SM содержит новое мощное ядро RT для операций трассировки.

Ядра CUDA стали более универсальными. Они могут работать как в режиме FP32, так и в INT32 в рамках одного тактового цикла. В прошлом поколении лишь половина ядер могла работать в INT32. Благодаря этому пропускная способность в режиме INT32 выросла вдвое. Современные GPU комбинируют разные типы нагрузок, и эта универсальность является ответом на востребованность разных типов вычислений.
Полная конфигурация GB202 насчитывает 192 SM, 24576 ядра CUDA, 192 ядра RT, 768 тензорных блока и 768 текстурных блока, плюс кэш L2 объемом в 128 МБ. Но для GeForce RTX 5090 идет вариант со 170 активными SM, что дает 21760 ядер CUDA, 680 тензорных ядер, 170 ядер RT и 680 текстурных ядер. И это почти на 33% больше количества вычислительных блоков у GeForce RTX 4090. Но обе видеокарты сохранили 176 ROP. Каждый SM по-прежнему оснащен 128 КБ кэш-памяти L1, а общий кэш L2 у RTX 5090 96 МБ вместо 72 МБ у RTX 4090.
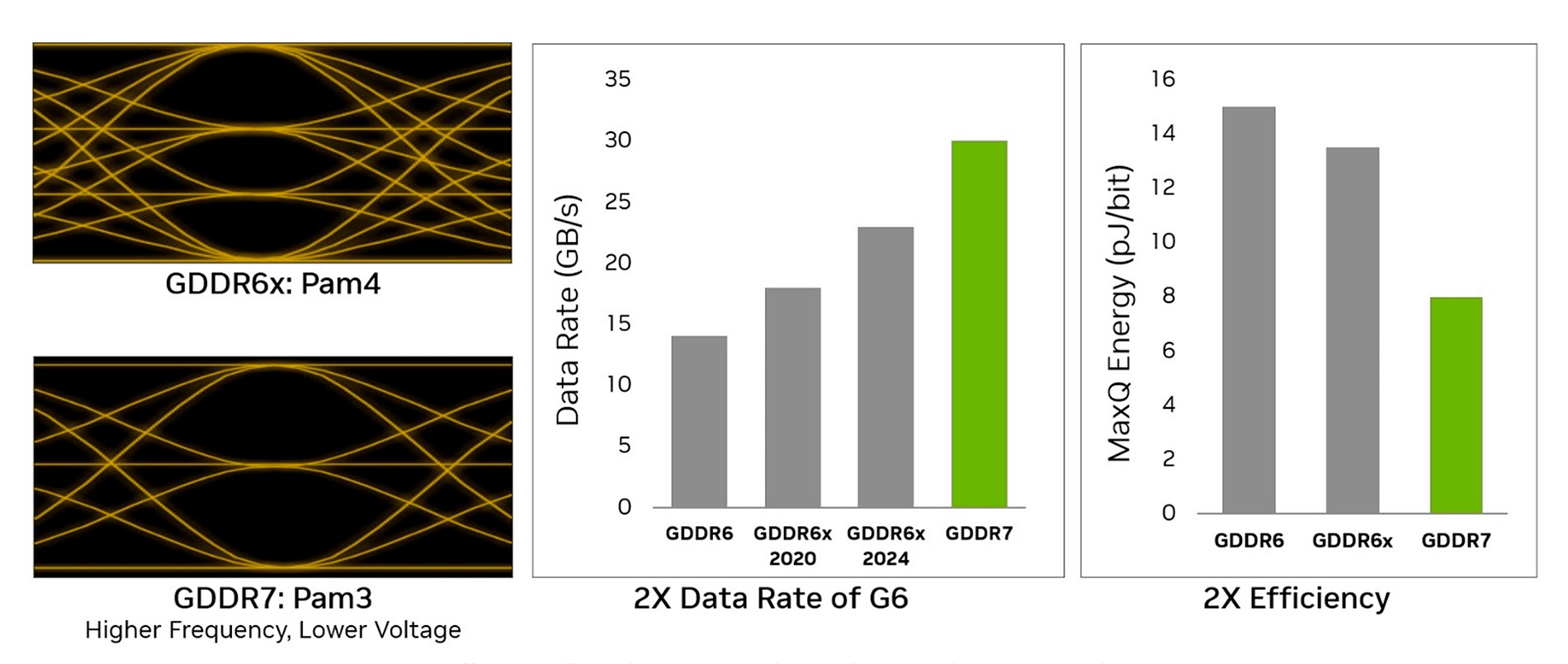
Процессор GB202 получил 16 32-битных контроллера памяти, что обеспечивает передачу данных по общей шине разрядностью 512 бит. Это же позволило оснастить GeForce RTX 5090 рекордным объем видеопамяти в 32 ГБ. Все новые видеокарты перешли на память GDDR7. Это новый стандарт памяти с технологией импульсно-амплитудной модуляции PAM3 с тремя уровнями сигнала, что позволяет кодировать 1,5 бита за такт. В памяти GDDR6X использовался метод PAM4, но повышение частоты упиралось в шум и дополнительные сложности в передаче сигнала. GDDR7 является компромиссным вариантом благодаря переработанной архитектуре тактирования и улучшенной подготовке ввода-вывода, плюс лучшая энергоэффективность. В итоге модули памяти GDDR7 у GeForce RTX 5090 обеспечивают скорость передачи сигнала 28000 Гбит/с при общей пропускной способности видеокарты 1792 ГБ/с. Для GeForce RTX 5080 используется еще более быстрая память 30000 Гбит/с, но в сочетании с шиной 256 бит.
Графические процессоры Blackwell получили улучшенные энергосберегающие механизмы и более гибкое управление Boost-частотами. При этом заявленное значение Boost Clock на 100 МГц ниже, чем у старого флагмана — 2407 МГц. Общая мощность видеокарты выросла до рекордных 575 Вт.
Для наглядности все данные по характеристикам GeForce RTX 5090 приведены вместе с параметрами старых флагманских моделей в одной таблице.
Характеристики GeForce RTX 5090
|
GeForce RTX 5090 |
GeForce RTX 4090 |
GeForce RTX 3090 Ti |
GeForce RTX 3090 |
GeForce RTX 2080 Ti |
|
|
Архитектура |
Blackwell |
Ada Lovelace |
Ampere |
Ampere |
Turing |
|
Ядро |
GB202 |
AD102 |
GA102 |
GA102 |
TU102 |
|
Техпроцесс, нм |
TSMC 4N (5 нм) |
TSMC 4N (5 нм) |
Samsung 8N |
Samsung 8N |
TSMC 12FFN |
|
Количество транзисторов, млн. шт |
92200 |
76300 |
28300 |
28300 |
18600 |
|
Площадь ядра, кв. мм |
750 (761,56) |
609 |
628 |
628 |
754 |
|
GPC |
11 |
11 |
7 |
8 |
6 |
|
TPC |
85 |
64 |
41 |
41 |
36 |
|
SM |
170 |
128 |
84 |
82 |
68 |
|
CUDA-ядра |
21760 |
16384 |
10752 |
10496 |
4352 |
|
Тензорные ядра |
680 (5-е поколение) |
512 (4-е поколение) |
336 (3-е поколение) |
328 (3-е поколение) |
544 (2-е поколение) |
|
Ядра RT |
170 (4-е поколение) |
128 (3-е поколение) |
84 (2-е поколение) |
82 (2-е поколение) |
68 (1-е поколение) |
|
Текстурные блоки TMU |
680 |
512 |
336 |
328 |
272 |
|
Блоки растеризации ROP |
176 |
176 |
112 |
112 |
88 |
|
FP32 FLOPS |
104,8 |
82,6 |
40 |
35,6 |
13,4 |
|
Tensor TOPS FP16 |
838 (3352 FP4) |
661 (1321 FP8) |
320 |
285 |
108 |
|
RT FLOPS |
317,5 |
191 |
84 |
69,5 |
69,5 |
|
L2 кэш |
96 МБ |
72 МБ |
6 МБ |
6 МБ |
5,5 MB |
|
Частота ядра (Base Clock), МГц |
2017 |
2235 |
1560 |
1395 |
1350 |
|
Частота ядра (Boost Clock), МГц |
2407 |
2520 |
1860 |
1695 |
1695 |
|
Шина памяти, бит |
512 |
384 |
384 |
384 |
384 |
|
Тип памяти |
GDDR7 |
GDDR6X |
GDDR6X |
GDDR6X |
GDDR6 |
|
Частота памяти (Data rate) |
28000 Гбит/с |
21000 Гбит/с |
21000 Гбит/с |
19500 Гбит/с |
14000 Гбит/с |
|
Объём памяти, ГБ |
32 |
24 |
24 |
24 |
11 |
|
ПСП памяти |
1792 ГБ/с |
1008 ГБ/с |
1008 ГБ/с |
936 ГБ/с |
616 ГБ/с |
|
Интерфейс |
PCI-E 5.0 |
PCI-E 4.0 |
PCI-E 4.0 |
PCI-E 4.0 |
PCI-E 4.0 |
|
Мощность TDP, Вт |
575 |
450 |
450 |
350 |
250 |
При беглом взгляде самые серьезные изменения заметны в подсистеме памяти. Но внутри вычислительных блоков тоже присутствуют есть важные изменения.
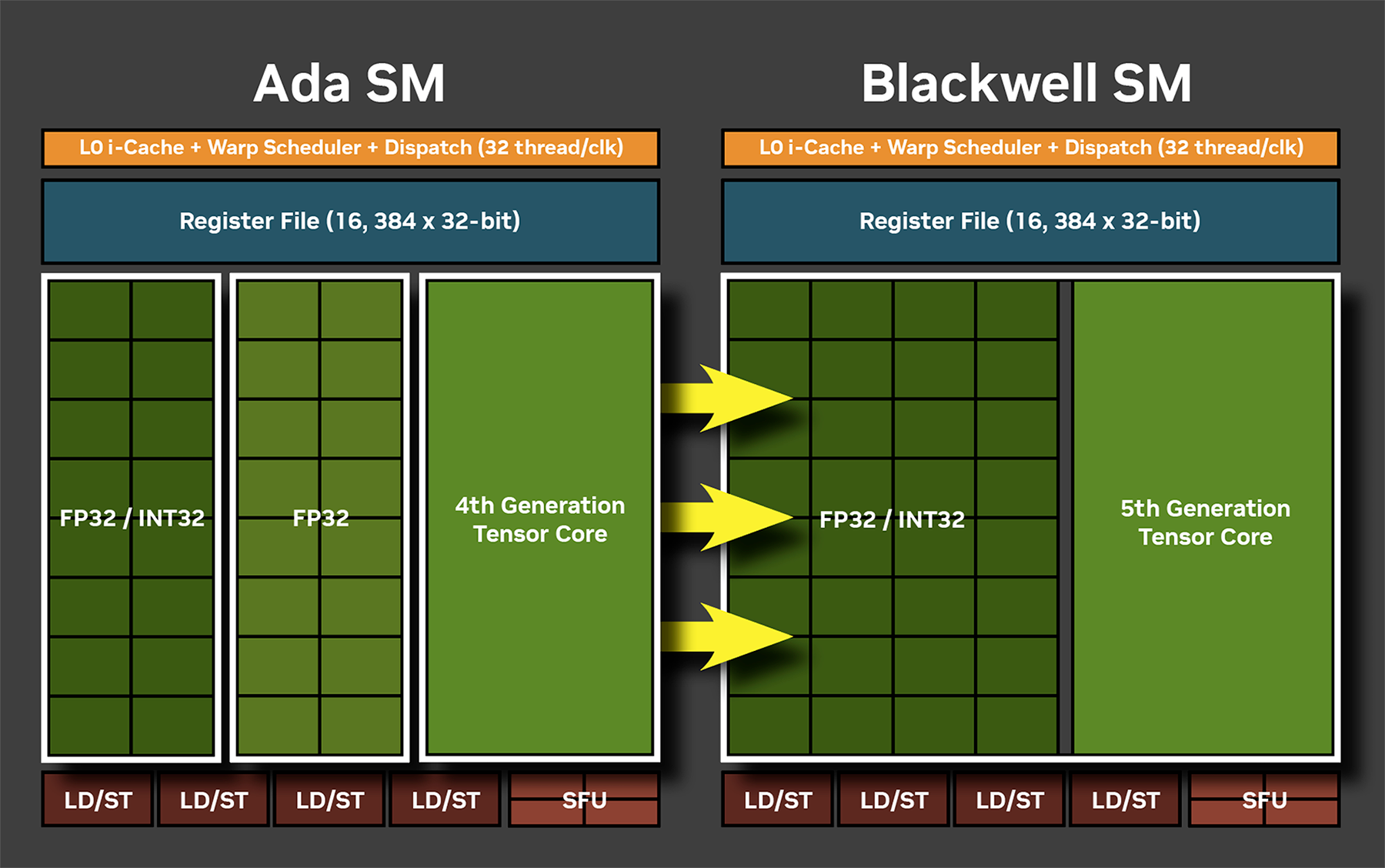
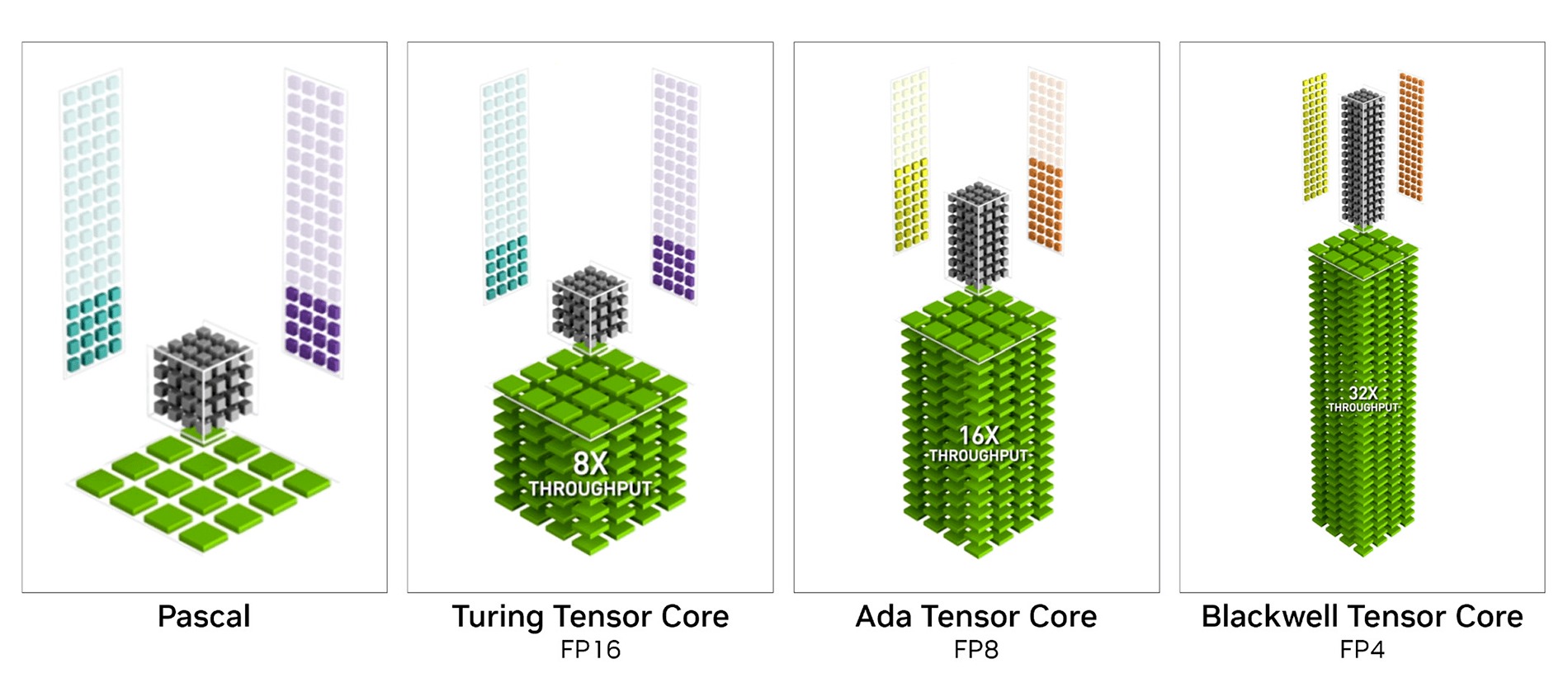
Тензорные ядра 5-го поколения
Blackwell использует тензорные ядра 5-го поколения. Впервые эти аппаратные блоки появились в специализированных ускорителях вычислений Volta в 2017 году, а второе поколение было внедрено в видеокарты Turing (GeForce RTX 20), где также впервые появились и ядра для ускорения рейтрейсинга. Первые тензорные ядра были рассчитаны на операции умножения матриц в формате FP16. Но по мере совершенствования и развития машинного обучения совершенствовались и эти блоки, получая поддержку новых востребованных форматов для ускорения общего потока вычислений. В Blackwell добавлена поддержка операций FP4 и FP6, а также новый FP8 Transformer Engine второго поколения, аналогичный тому, что используется в GPU для центров обработки данных. Новые форматы позволяют использовать более низкий уровень квантования, уменьшая размеры моделей ИИ и повышая скорость расчетов. И благодаря внедрению FP4 компания NVIDIA заявляет о совокупной пиковой производительности в операциях ИИ до 3352 TOPS (триллион операций в секунду). Для сравнения, GeForce RTX 4090 в FP8 обеспечивает 1321 TOPS. При работе в формате FP16 пиковые показатели этих же видеокарт 838 и 661 TOPS соответственно.
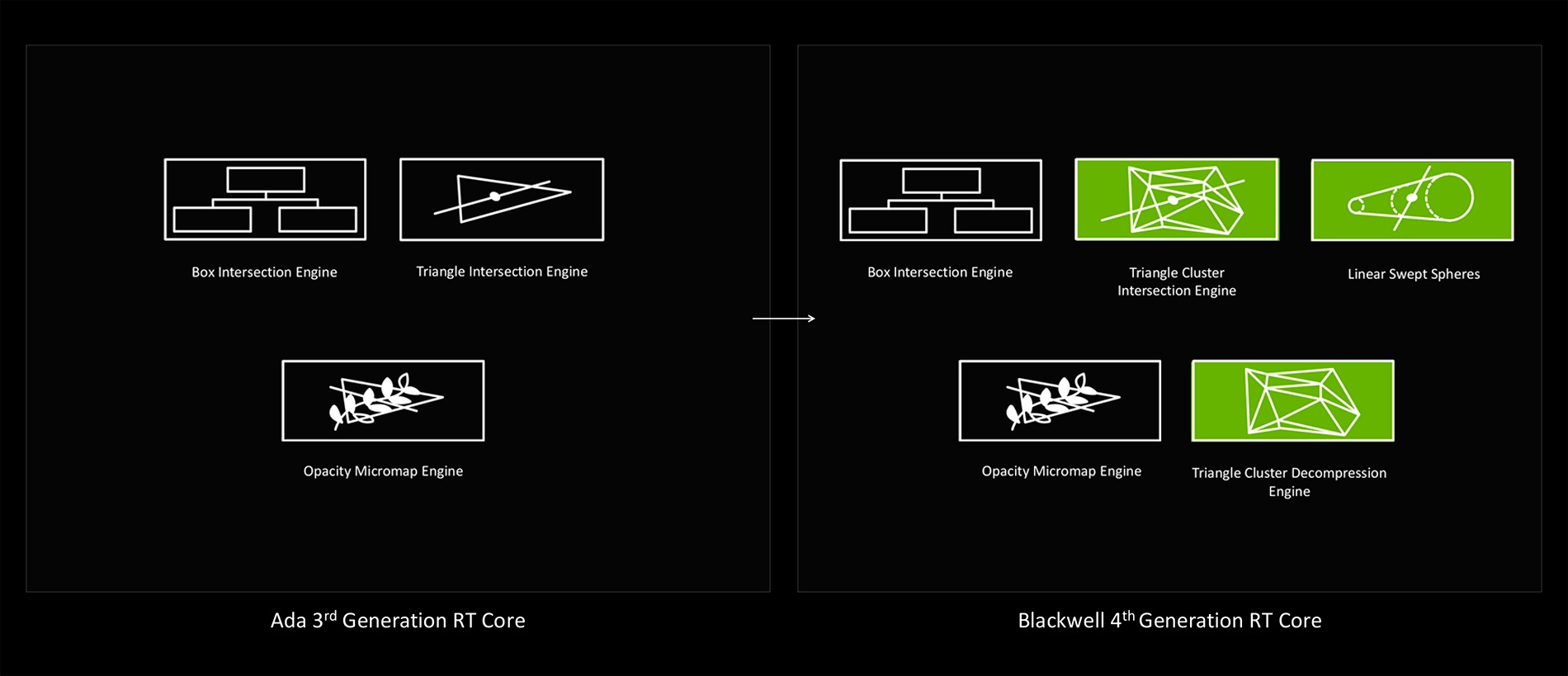
RT-ядра 4-го поколения
Blackwell использует ядра RT 4-го поколения, которые стали еще мощнее и получили некоторые новые функции. Они содержат вычислительные блоки для ускорения основного алгоритма Bounding Volume Hierarchy (BVH), Ray-Triangle Intersection для просчета пересечения луча с треугольником и ограничивающим прямоугольником. Также RT получил Opacity Micromap Engine для оптимизации просчета геометрии и работы новой технологии RTX Mega Geometry. Плюс Triangle Cluster Compression Engine для оптимизации работы с геометрией и Linear Swept Spheres для ускорения трассировки для тонкой геометрии, например, для шерсти и волос.
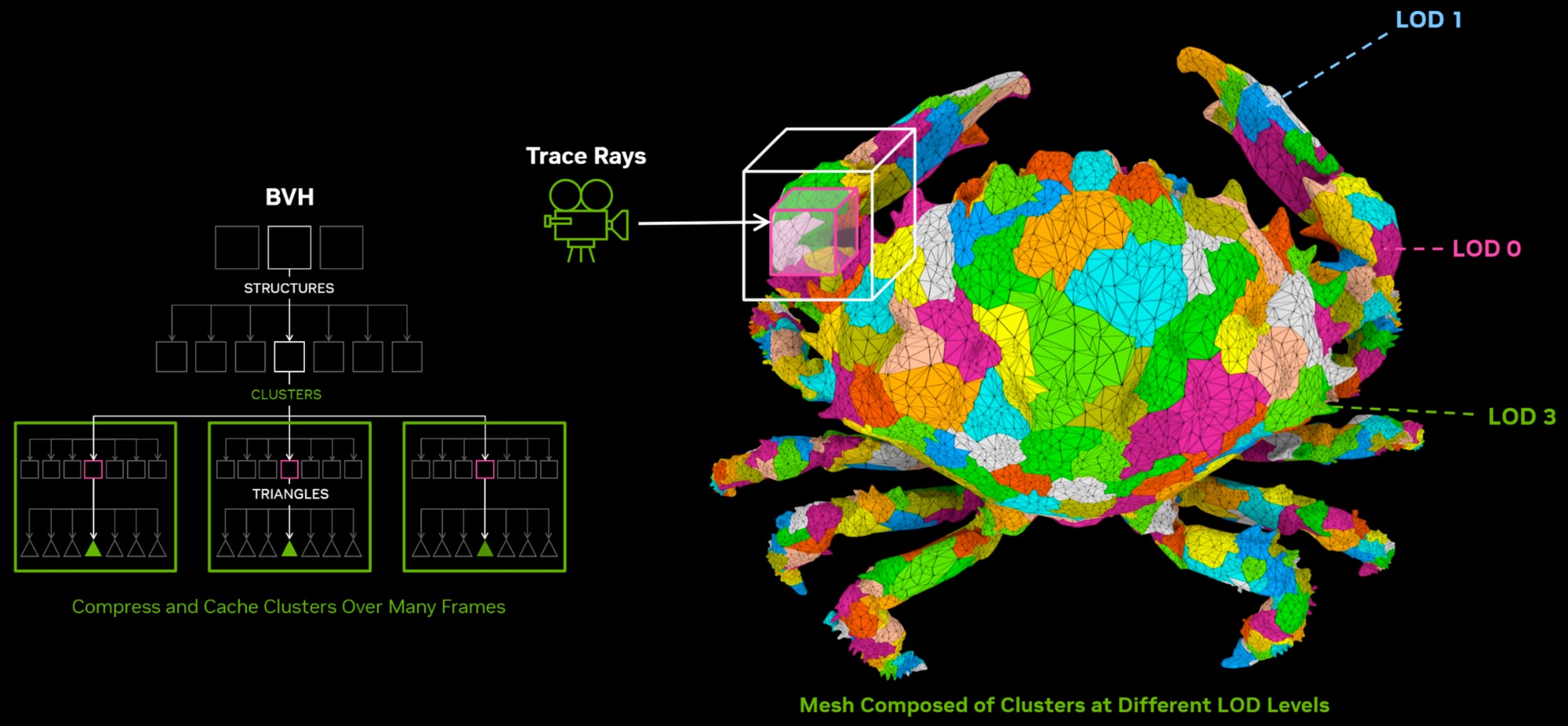
RTX Mega Geometry
Технология RTX Mega Geometry является одним из важных нововведений, она позволяет выполнять сложную трассировку современным движкам с большим уровнем детализации, например, для Unreal Engine 5 с Nanite. Это оптимизирует обработку сложных сцен и позволит повысить качество теней, отражений и непрямого освещения. Современные движки используют кластерную систему загрузки для изменения LOD, что требует частого изменения сетки геометрии при просчете иерархии BVH для трассировки. В режиме реального времени при сложной геометрии это создает невероятно высокую нагрузку. Mega Geometry оптимизирует процесс, работая с кластерами треугольников в качестве первоначальных примитивов, а потом использует эти данные для построения конечной более детальной структуры BVH. Также GPU лучше управляет всем процессом, минимизируя обращения к CPU.
Специально для сверхсложных сцен предлагается вариант Mega Geometry со структурами Partitioned Top Level Acceleration Structure, где оптимизация базируется на факте того, что большинство объектов в сцене статичны от одного кадра к другому. Это позволяет работать со статичными и динамичными секторами кадра.
Также Mega Geometry позволяет реализовать и другие механизмы ускорения трассировки для геометрических методов — например, ускорение обработки поверхностей с иерархическим разбиением (Subdivision Surfaces).
Mega Geometry состоит из новых расширений API RTX, определенных оптимизаций в ядрах RT Blackwell и на уровне драйвера. Новые функции и структуры PTLAS поддерживаются в наборе инструкций DirectX 12 (DXR), Vulkan и OptiX 9.0. А новые тензорные ядра специально проектированы для Mega Geometry.
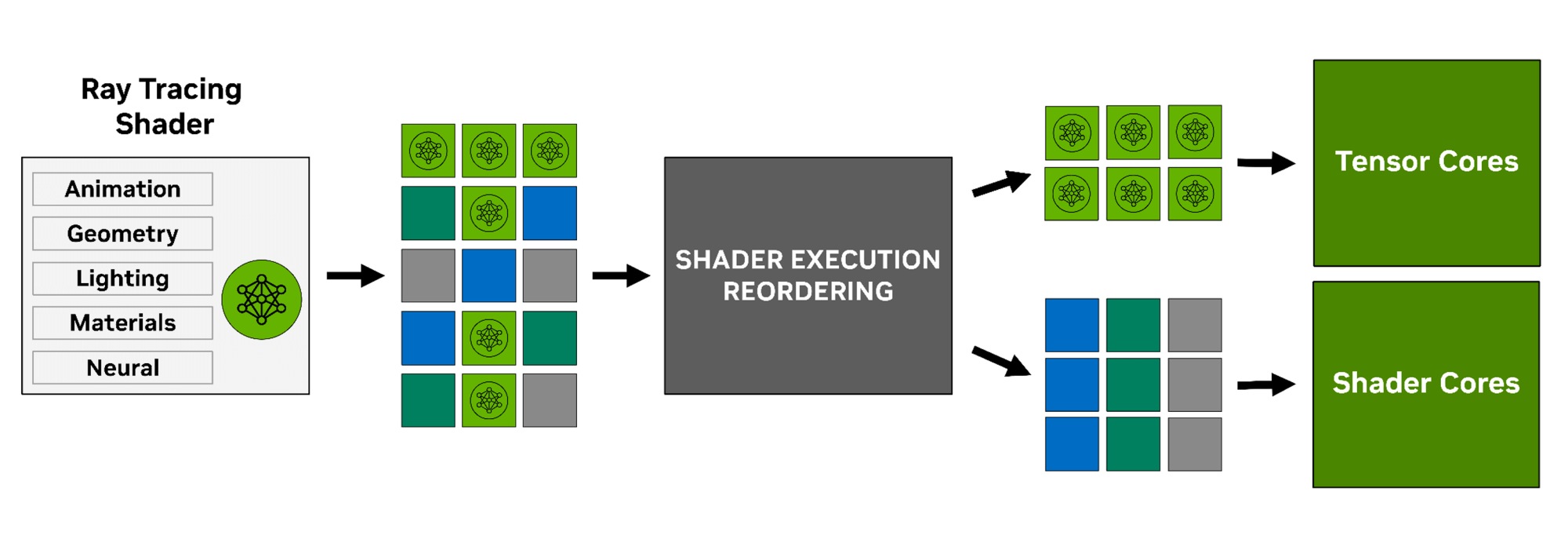
Shader Execution Reordering
В архитектуре Blackwell улучшены механизмы Shader Execution Reordering (SER), что впервые внедрены в Ada Lovelace. SER 2.0 улучшает распределение вычислительных потоков для максимальной загрузки GPU в приложениях с разным типом нагрузок, включая более эффективное распределение задач для тензорных ядер. Упоминается, что новая логика SER работает в два раза эффективнее.
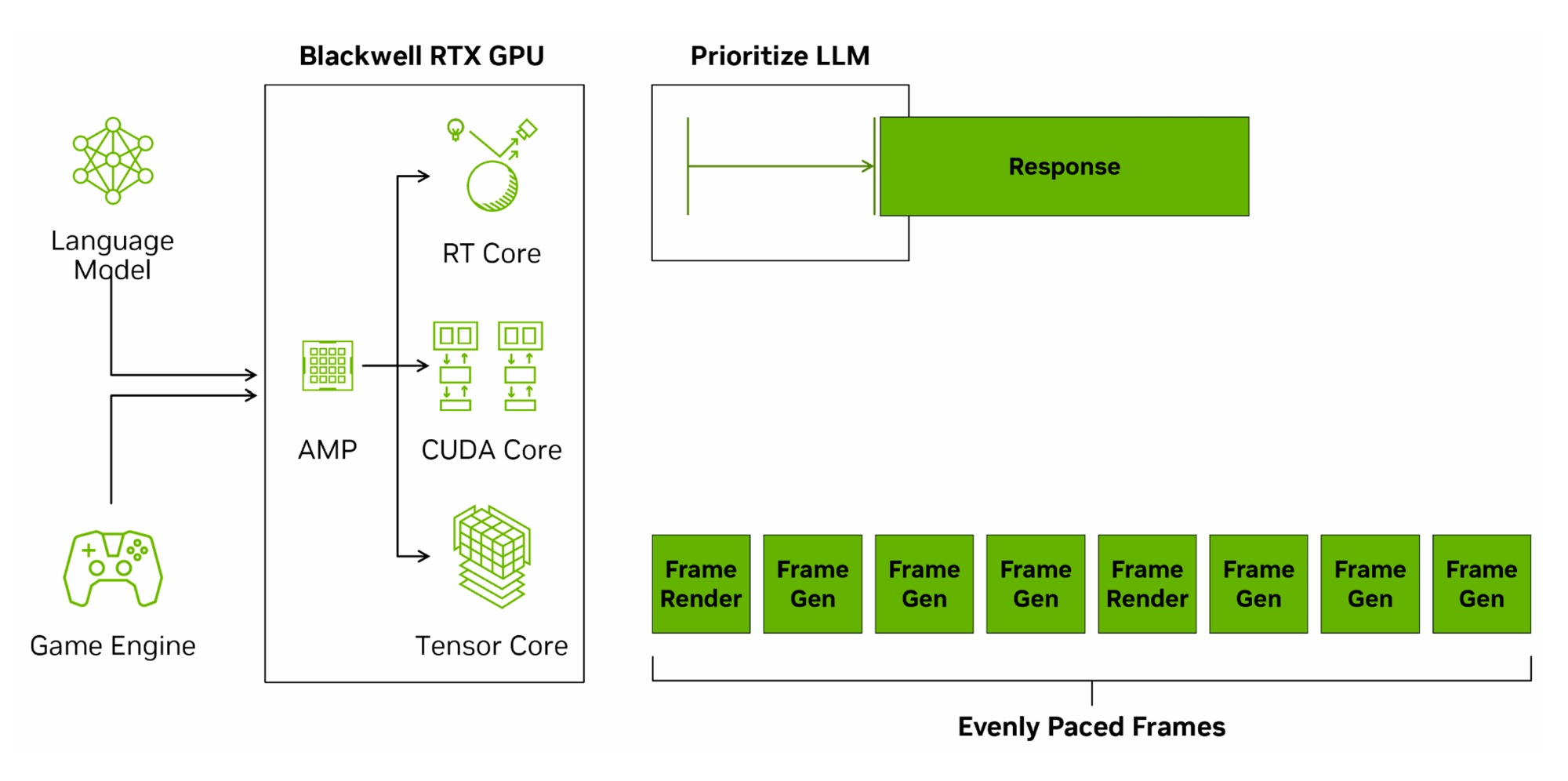
AI Management Processor
Выше мы упоминали о внедрении AI Management Processor (AMP). Это программируемых планировщик для более эффективного управления разным типом нагрузок в масштабах всего GPU. Аппаратно он реализован в виде отдельного сопроцессора RISC-V, обеспечивая более быстрое планирование контекстов графического процессора с меньшей задержкой, чем предыдущие методы. AMP берет на себя часть задач планирования, которые ранее выполнялись на CPU. Такое разрешение GPU управлять собственной очередью задач может привести к меньшей задержке из-за снижения количества двусторонних коммуникаций между графическим процессором и центральным процессором. Это улучшает многозадачность при работе нескольких приложений, а и в играх может обеспечить более плавную частоту кадров.
Улучшенный кодировщик NVENC и вывод видео
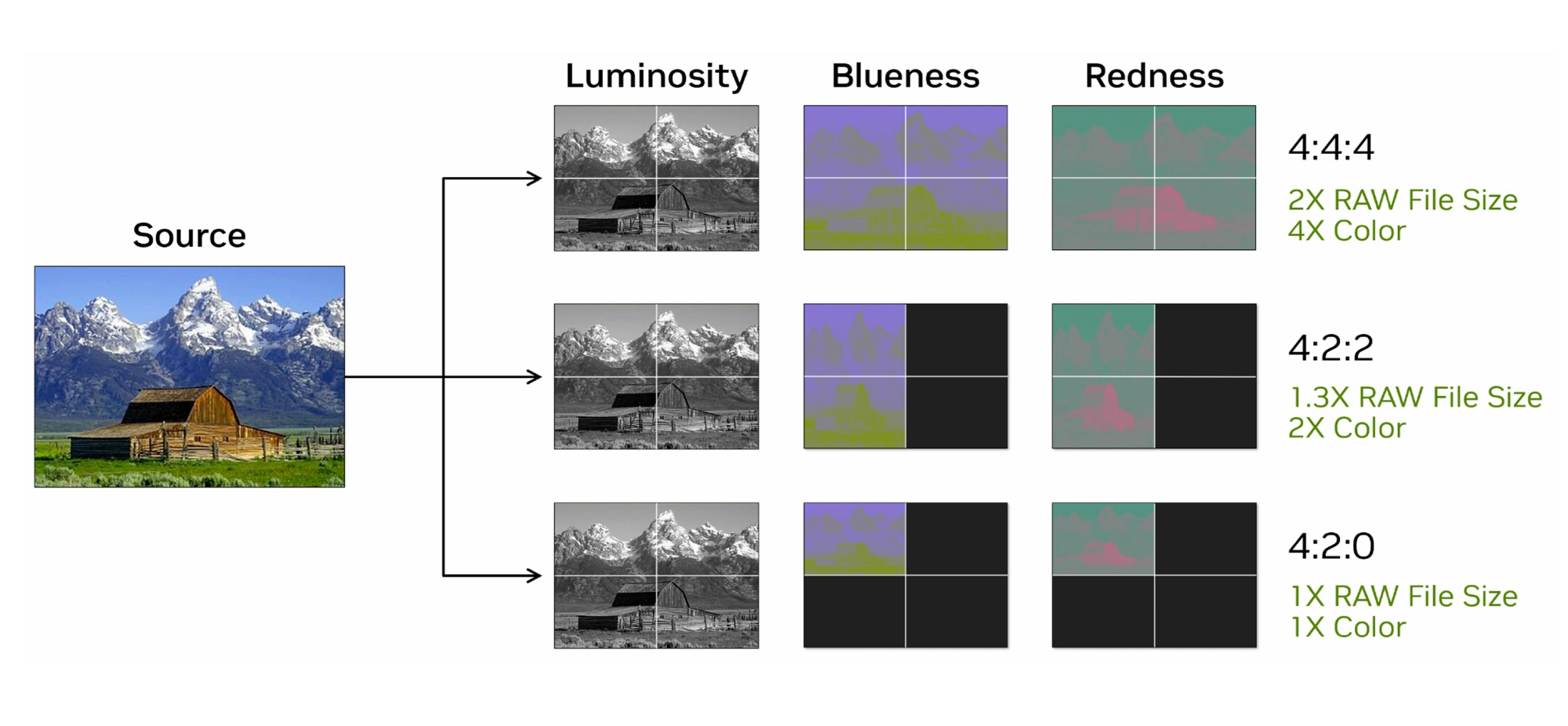
Серьезные изменения в блоках кодирования/декодирования видео. Все прошлые GeForce поддерживали стандарт кодирования цвета 4:2:0. Blackwell поддерживает цветовую субдискретизацию 4:2:2, что ранее было доступно лишь в профессиональных решениях. Вместо хранения цвета в виде значений красного, зеленого и синего (RGB), цвет сохраняется как яркость (Y), синяя разница цветности (U) и красная разница цветности (V). Формат кодирования YUV 4:4:4 требует большой пропускной способности, а файлы занимают больший объем. Формат используется в профессиональной среде, в том числе он распространен в профессиональных камерах. Такое кодирование полезно для контента HDR и для сохранения мелких деталей на видео.
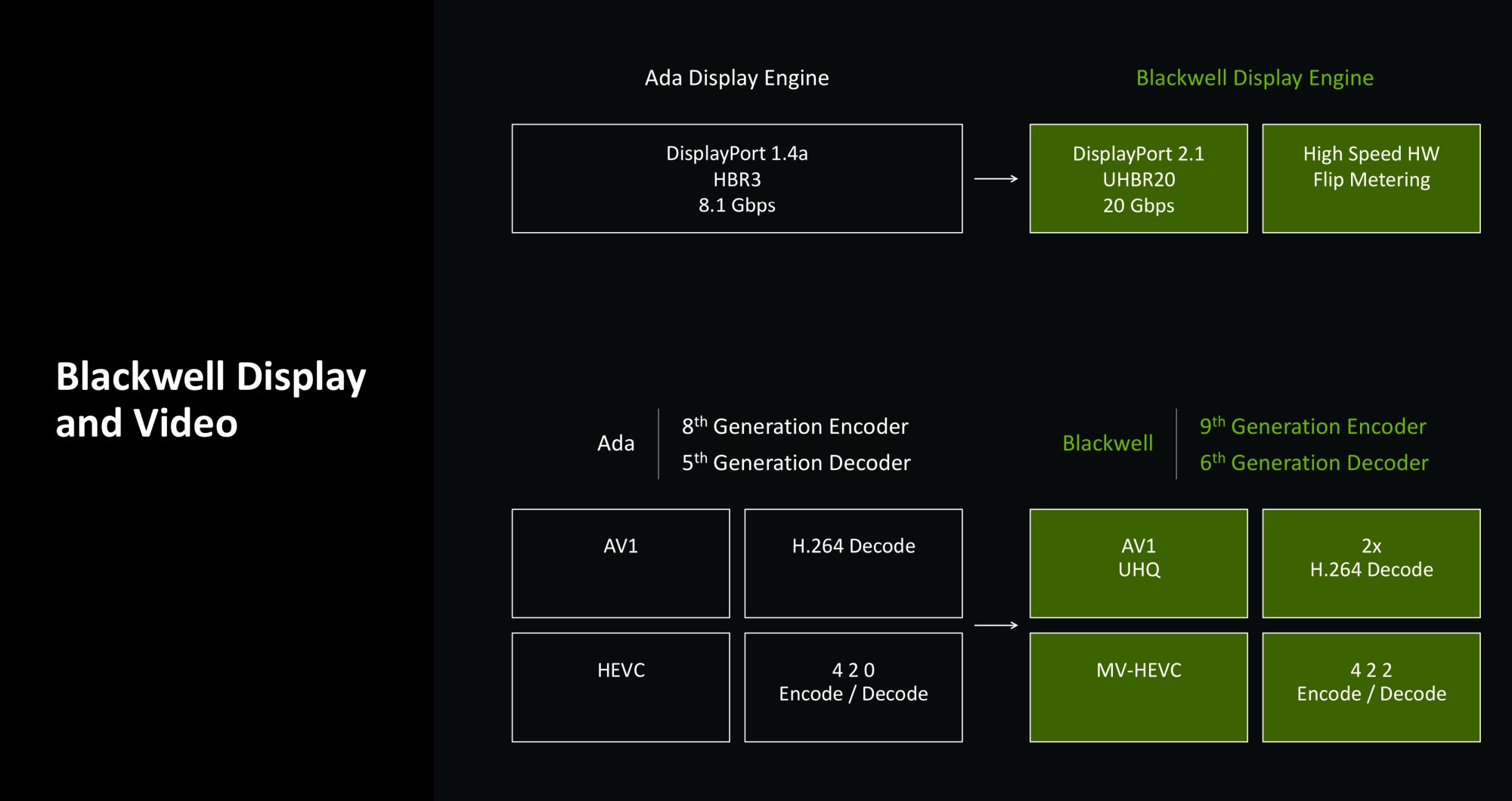
Обновлены блоки NVENC для аппаратного кодирования видео обновлены до 9-го поколение. Кроме нового цветового формата они также предложат улучшение качества работы с AV1 и HEVC на 5%, поддержку нового режима AV1 Ultra High Quality (UHQ). Аппаратные декодеры NVENC обновлены до 6-го поколения, предлагая полную поддержку H.264 и HEVC 4:2:2 и повышение скорости работы с H.264. При этом GeForce RTX 5090 насчитывает три кодера и два декодера, ускоряя обработку видео.
Разница в скорости экспорта видео может быть до четырёх раз, если сравнивать с GeForce RTX 3090, который имеет один кодировщик.
|
|
GeForce RTX 5090 |
GeForce RTX 4090 |
GeForce RTX 3090 |
|
Аппаратный кодировщик видео |
3 x NVENC (9th Gen) |
2 x NVENC (8th Gen) |
1 x NVENC (7th Gen) |
|
Аппаратный декодер видео |
2 x NVDEC (6th Gen) |
1 x NVDEC (5th Gen |
1 x NVDEC (5th Gen) |
Видеокарты оснащены DisplayPort 2.1b с пропускной способность до 80 Гбит/с и поддержкой режима передачи UHBR 20 (сверхвысокая скорость данных 20 Гбит/с на линию). DisplayPort 2.1b UHBR 20 позволяет запускать дисплеи с высоким разрешением, используя максимально возможные частоты обновления: 8K (7680x4320) @ 165 Гц (требуется DSC) и 4K (3840x2160) @ 480 Гц (требуется DSC). Для высоких скоростей соединения требуется сертифицированный кабель DP80LL.
Управление питание и улучшения Max-Q
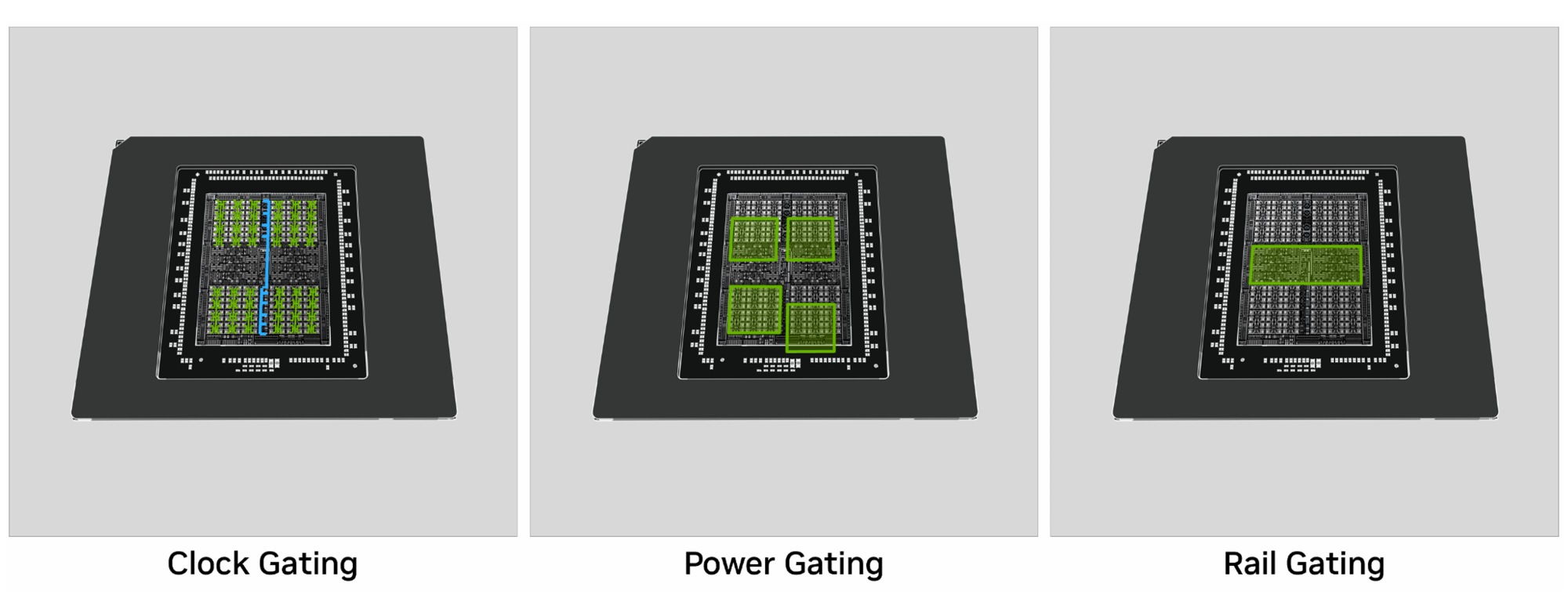
Архитектура Blackwell получила важные улучшения в наборе технологий Max-Q, включая изменения в механизмах управлением питания и переключением частот. Плюс энергоэффективный режим работы памяти GDDR7, быстрая отзывчивость при переходе в режим сна и технология DLSS 4, которая «экономит» ресурсы чипа, генерируя дополнительные кадры.

Это первое столь серьезное изменения в архитектуре NVIDIA за 10 лет. Новая система управления питанием позволяет раздельно регулировать напряжения в разных сегментах чипа и отключать их в моменты небольшого простоя, экономя энергию. Это снижает общее энергопотребление чипа в режиме ожидания и при невысокой изменчивой нагрузке. И это крайне важно для мобильных GPU, особенно при работе от аккумулятора.
Чип быстрее переключается в состояние с низким потреблением энергии. Blackwell в 10 раз быстрее входит в состояние глубокого сна чем Ada, что позволяет значительно экономить энергию в состоянии сна с самым низким энергопотреблением, обеспечивая дополнительную экономии энергии.
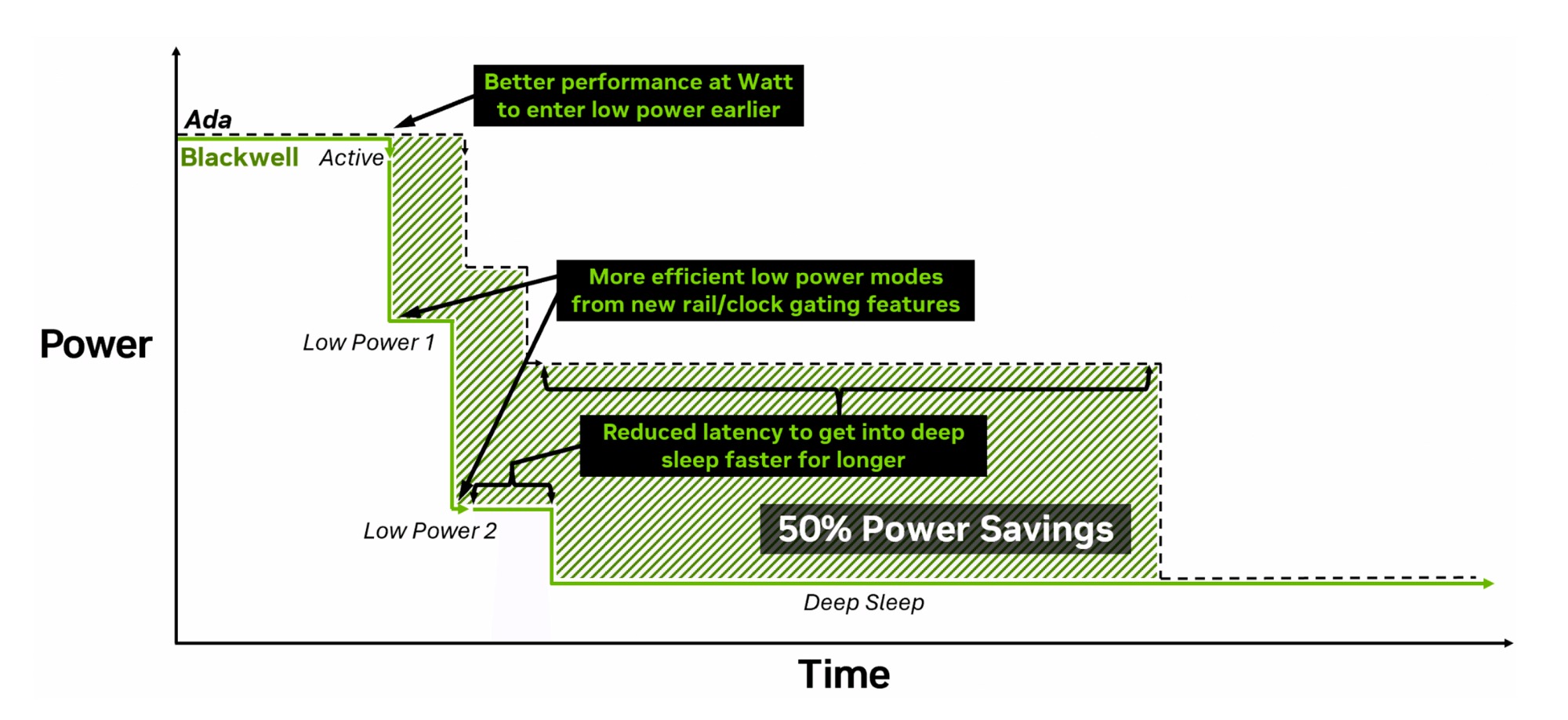
Ускорен механизм переключения частот. Теперь частоты GPU переключаются в 1000 раз быстрее, чем в прошлых поколениях. Благодаря этому Blackwell быстрее реагирует на изменчивые динамические нагрузки, повышая или понижая таковую частоту. Это позволяет лучше раскрыть весь потенциал GPU в рамках заданного лимита мощности и быстрее переходить в энергосберегающие режимы при низкой нагрузке.
