Недавно компания AMD представила свой высокопроизводительный ускоритель вычислений ИИ. В своем блоге компания NVIDIA обратила внимание, что в презентации конкурента использовалось неоптимизированное программное обеспечение. Недавно компания обновила свою программную платформу TensorRT-LLM для программной оптимизации с большими языковыми моделями.

При использовании TensorRT-LLM результаты будут совершенно иные, позволяя достичь почти двукратного ускорения в определенных задачах. В качестве ответа компания привела результаты тестирования производительности одного сервера NVIDIA DGX H100 с восемью графическими процессорами NVIDIA H100 с моделью ИИ Llama 2 70B.
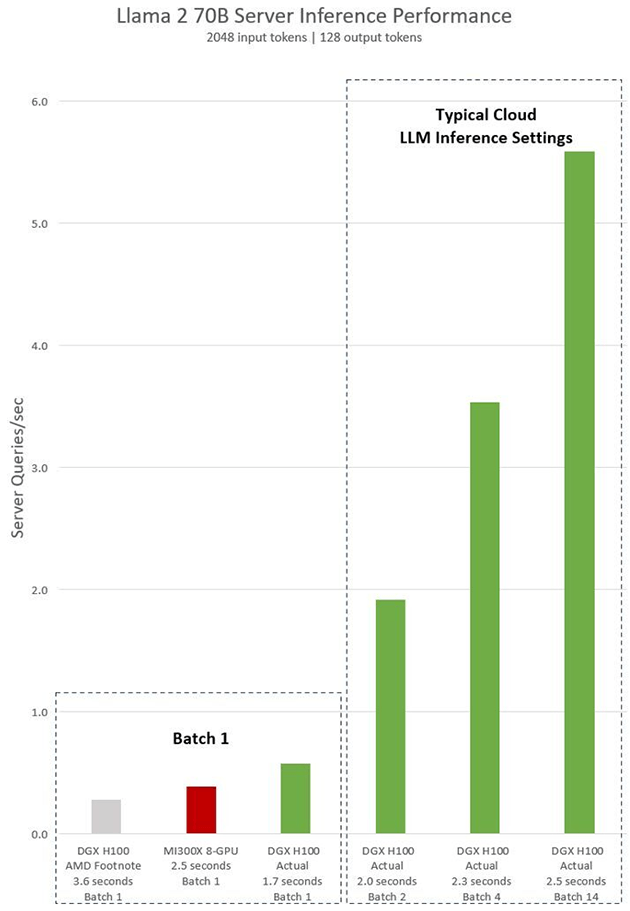
В идентичных условиях при обработке Batch-1 преимущество H100 над AMD MI300X более 40%. Это тестирование по схеме один запрос за один пакет. Но в ЦОД часто объединяют запросы в более крупные пакеты и увеличивают общее количество выводов сервера в секунду. И такая пакетная обработка у Nvidia еще эффективнее. Используя фиксированное время отклика в 2,5 секунды, сервер DGX H100 с 8 графическими процессорами может обрабатывать более пяти выводов Llama 2 70B в секунду, в то время как при одиночном запросе это менее одного вывода в секунду.
Источник: NVIDIA