Все мы с нетерпением ждали новых анонсов от компании NVIDIA. И они произошли на виртуальной презентации, которая прошла 14 мая вместо отмененного выступления на GPU Technology Conference 2020. Глава компании, Дженсен Хуанг, анонсировал новую архитектуру Ampere и первое устройство на ее основе — ускоритель вычислений NVIDIA A100 (Tesla A100). Также были представлены новые инициативы в области высокопроизводительных HPC-систем, искусственного интеллекта и робототехники. Все это напрямую не касается игровых видеокарт, но NVIDIA A100 дает старт новому поколению GPU, и к концу года мы точно увидим GeForce следующего поколения. Поэтому интересно оценить изменения и преимущества нового графического чипа, который задает направление для развития игровых GPU.

Начнем с того, что NVIDIA A100 — это строго вычислительное устройство, которое будет применяться в серверных системах обработки данных и выпускается в соответствующем форм-факторе SXM4. В будущем вероятно будут представлены варианты под PCI-E, что позволит устанавливать их в обычные рабочие станции и ПК.
В последние годы наметился бурный рост облачный технологий с ускорением на GPU. Это глубокое обучение систем искусственного интеллекта, анализ данных, научные вычисления, геномика, видеоаналитика и услуги 5G, рендеринг графики, облачные игры и многое другое. Графические ускорители NVIDIA являются самыми передовыми устройствами для ускорения операций связанных с ИИ. Выпуск Tesla V100 в 2017 году стал новой вехой в развитии компании, позволив закрепиться в области устройств для центров обработки данных. При этом Tesla V100 так и осталась единственным устройством на процессоре Volta (не считая ограниченной серии TITAN V), поскольку более поздние игровые решения использовали оптимизированную архитектуру Turing. В случае Ampere уже заявлено, что новая архитектура будет актуальна и для игровых видеокарт, но там безусловно будут свои упрощения, оптимизации и обрезание лишних функций. Пока NVIDIA не раскрывает все архитектурные нюансы, отмечая основные особенности и те изменения, что важны непосредственно для вычислений.
В дизайне нового GPU компания NVIDIA отмечает пять ключевых моментов:
- Архитектура NVIDIA Ampere
- Тензорные ядра третьего поколения TF32
- Технология виртуализации Multi-instance GPU (MIG)
- Шина NVLink третьего поколения
- технология Structural Sparsity для удвоения производительности

Основой нового Tesla A100 является графический процессор GA100. Это первый 7-нм GPU от NVIDIA, выпущенный на заводах TSMC. И это крупнейший 7-нм процессор в мире, насчитывающий 54 миллиарда транзисторов, что в 2,5 раз больше количества транзисторов в GPU GV100 (Tesla V100). Площадь GA100 достигает 826 мм², что минимально отличается от 815 мм² у GV100. Количество ядер CUDA выросло до 6912 (у Volta было 5120). Ключевой особенностью старших GPU в ускорителях Tesla является использование стеков памяти HBM, которые расположены на одной подложке с графическим чипом. Используется уже шесть модулей памяти HBM2 , что позволяет обмениваться данными по общей шине разрядностью 5120 бит, а объем памяти достиг внушительных 40 ГБ! Для сравнения: в V100 32 ГБ видеопамяти с шиной 4096 бит. При частоте модулей памяти 2,4 ГГц пропускная способность памяти A100 достигает внушительного значения в 1,6 Тбайт/с вместо 900 Гбайт/с у V100.

Процессор GA100 состоит из 8 кластеров GPC, каждый из которых содержит 8 TPC по 2 SM. Итого получается 128 мультипроцессоров SM (у Volta GV100 их было 84). Такой гигантский GPU оперирует 8192 CUDA-ядрами FP32 и 512 тензорными ядрами для операций глубокого обучения. Однако для A100 заявлено 7 активных кластеров и 6912 ядер CUDA, плюс 432 тензорных ядра. То есть представленный ускоритель получил урезанный процессор, где деактивирован один кластер и несколько дополнительных SM. Это может быть связано с необходимостью повысить количество годных кристаллов. И нельзя исключать, что по мере совершенствования технологии производства когда-нибудь выйдет более мощный ускоритель с полной конфигурацией GPU GA100. У процессора 12 контроллеров памяти, которые обеспечивают работу с 6-ю модулями памяти HBM2. Объем кэш-памяти L2 достиг внушительных 40 МБ. Разделение памяти на два блока позволяет уменьшить задержки при обращении к L2, каждый раздел L2 кэширует данные для доступа к памяти от SM в GPC. Новая структура L2 обеспечивает рост пропускной способности в 2,3 раза при работе программной модели CUDA. А высокий объем кэша востребован для HPC-вычислений и ИИ. Поскольку для Tesla A100 заявлен объем памяти 40 ГБ, у нас работает 5 модулей из 6, что вполне логично. Управляет кластерами новый движок распределения вычислений MIG. Есть поддержка интерфейса PCI Espress 4.0, но Tesla A100 работают через более быстрый интерфейс NVLink третьего поколения. Эта версия NVLink обеспечивает скорость передачи данных до 50 Гбит/с в двух направлениях на один канал, и до 12 соединений с общей пропускной способностью 600 Гбайт/с.
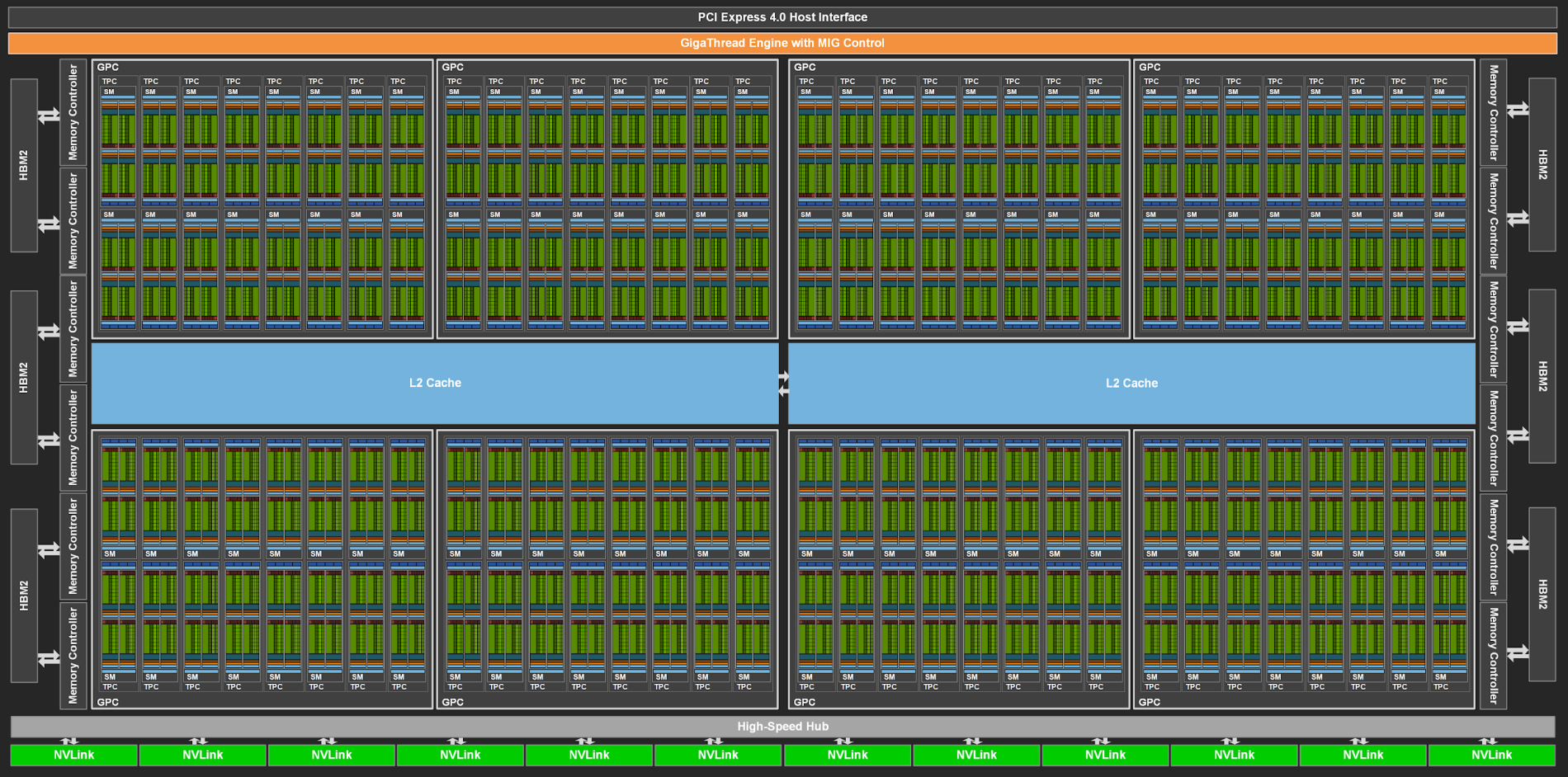
Структура мультипроцессоров SM напоминает аналогичные блоки Turing, но с некоторыми дополнениями. Это 64 вычислительных ядра, которые одновременно выполняют операции INT32 и FP32. У Volta/Turing было по 8 тензорных ядер на SM, у Ampere это 4 усовершенствованных тензорных ядра. Объем кеш-памяти L1 достиг 196 КБ (у Turing 96 КБ, у Volta 128 КБ). Это комбинированный кэш данных и функций, что упрощает программный доступ. Также мы видим у SM 4 текстурных блока, и полноценный GA100 мог бы оперировать 512 блоками TMU. Нет блоков RT, которые вероятно вернутся в игровых GPU Ampere, ориентированых непосредственно на графику.
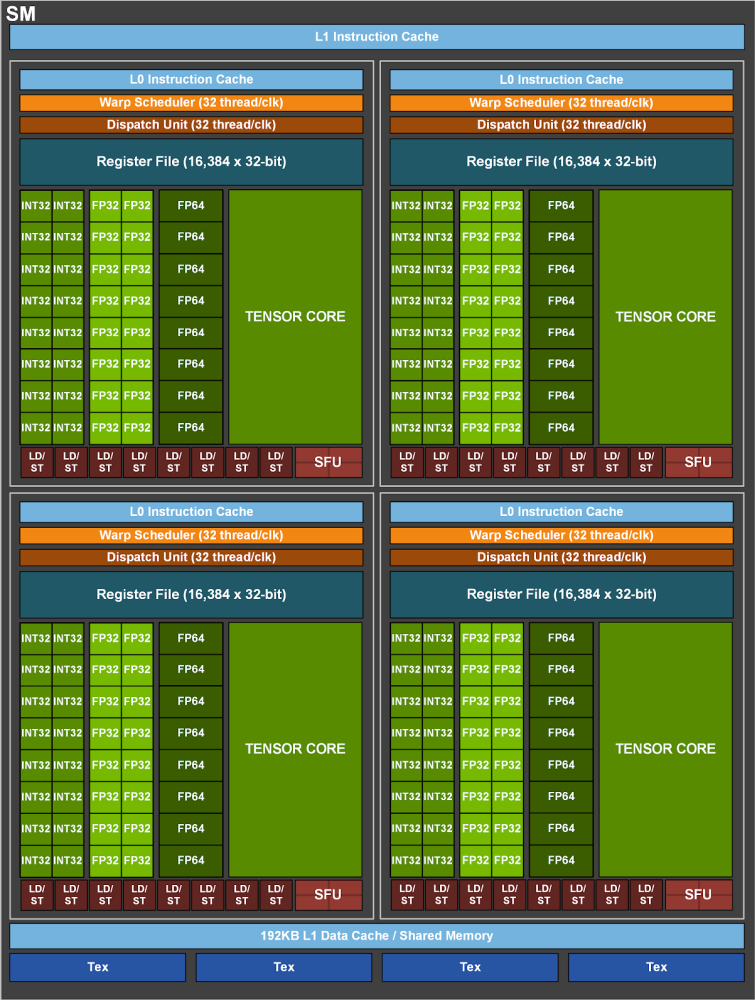
В итоге имеем процессор, значительно нарастивший количество вычислительных блоков и с увеличенным объемом кэша. Серьезно возросла пропускная способность памяти. Рабочая частота GPU была немного снижена — заявлен Boost Clock 1410 МГц вместо 1530 МГц у Volta. Такой прогресс не обошелся без роста энергопотребления. Для A100 заявлен TDP 400 Вт, что выше TDP прошлых продуктов семейства Tesla.
|
Tesla A100 |
Tesla V100 |
Tesla P100 |
|
|
Архитектура |
Ampere |
Volta |
Pascal |
|
GPU |
GA100 |
TU104 |
GP102 |
|
Количество транзисторов, млрд. шт |
54,2 |
21,1 |
15,3 |
|
Техпроцесс, нм |
7 nm N7 |
12 nm FFN |
16 nm FinFET+ |
|
Площадь ядра, кв. мм |
862 |
815 |
620 |
|
SM |
108 |
80 |
56 |
|
Количество потоковых процессоров CUDA |
6912 |
5120 |
3584 |
|
Количество тензорных ядер |
432 |
640 |
- |
|
Количество текстурных блоков TMU |
432 |
320 |
224 |
|
Частота ядра Boost Clock, МГц |
1410 |
1530 |
1480 |
|
Кэш L2, МБ |
40 |
6 |
4 |
|
Шина памяти, бит |
5120 |
4096 |
4096 |
|
Тип памяти |
HBM2 |
HBM2 |
HBM2 |
|
Частота памяти, МГц |
2430 (1215 DDR) |
1756 (878 DDR) |
1406 (703 DDR) |
|
ПСП памяти |
720 GB/sec |
900 GB/sec |
1,6 TB/sec |
|
Объём памяти, ГБ |
40 |
32/16 |
16 |
|
NVLink |
|
|
|
|
Интерфейс |
SXM4 |
SXM2/PCI-E 3.0 |
SXM |
|
Мощность TDP, Вт |
400 |
300 |
300 |
Производительность блоков SM повышена за счет новых функций и инструкций. Важные изменения произошли в тензорных ядрах. Tensor Core третьего поколения поддерживают новые типы вычислений, позволяя ускорить операции в задачах глубокого обучения. Тензорные ядра обеспечивают ускорение вычислений TF32, IEEE FP64 для HPC и выполнение специальных инструкций BF16 с производительностью FP16. Сейчас стандартная математика в сфере ИИ предполагает вычисления стандарта FP32 через TensorFloat-32 (TF32). Ampere ускоряет тензорную математику с TF32 (точность FP16), поддерживая входные и выходные данные стандарта FP32.
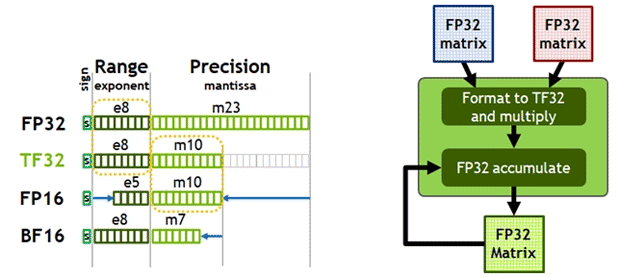
Поддерживается функция автоматической смешанной точности Automatic Mixed Precision (AMP) FP16 для обучения ИИ. И для максимальной скорости тренировки нейросети используются вычисления смешанной точности FP16 или BF16. Это обеспечивает увеличение пропускной способности в 2 раза в сравнении с TF32, в 16 раз в сравнению с FP32 на A100 и до 20 раз в сравнению с FP32 на V100.
Поддержка технологии Sparsity позволяет использовать специальное структурированное распределение матричных данных в нейронных сетях для удвоения пропускной способности. Это специальный метод удаления менее значимых весов сети без значимой потери в общей точности вывода.
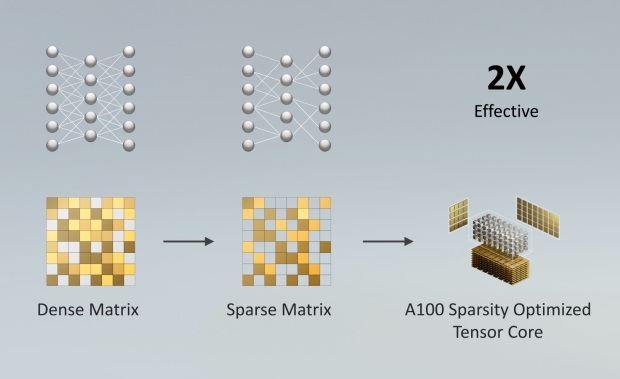
Приложения научной и исследовательской сферы часто используют вычисления двойной точности FP64. Специально для HPC-вычислений введены новые тензорные операции, ускоряющие FP64. Например, новая команда умножения-сложения матрицы двойной точности на GA100 заменяет восемь инструкций DFMA на GV100. Тензорные ядра используются наряду со стандартными CUDA-ядрами для ускорения алгоритмов ИИ, HPC-вычислений и других задач. И новый процессор Ampere быстрее обрабатывает математику FP64 по сравнению с другими GPU при меньшем объемом работы. Преимущество относительно Volta достигает 2,5-5 раз, а при обработке INT8 вместе с технологией Sparsity преимущество до 20 раз.
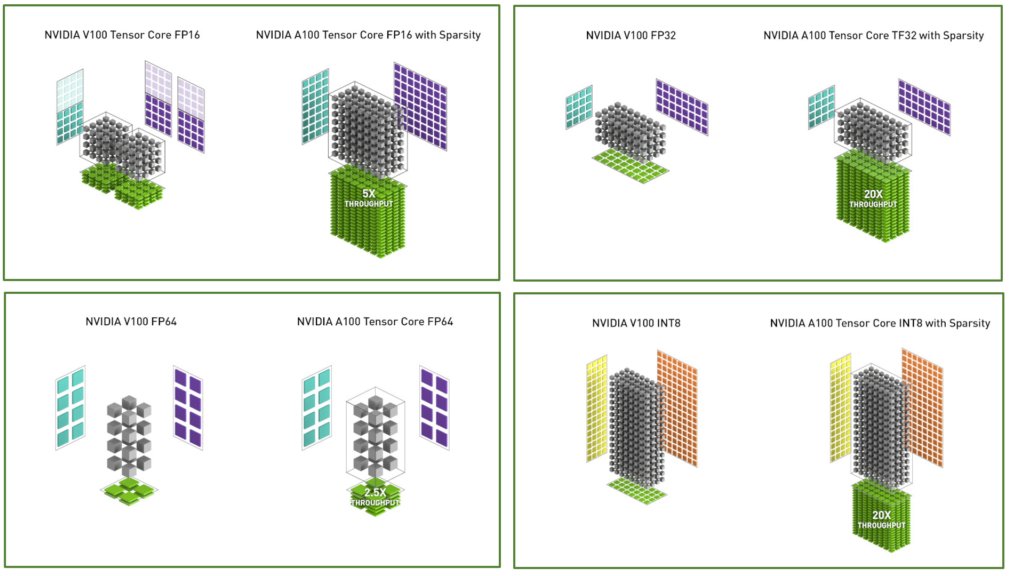
В итоге мы имеем ситуацию, когда при прямом сравнении вычислительной мощности Tesla A100 и Tesla V100 разница не всегда внушительная. Это 19,5 Терафлопс против 15,7 Терафлопс в FP32 и 9,7 Терафлопс против 7,8 Терафлопс в FP64. Но обновленные тензорные ядра и новые методы смешанных вычислений позволяют достичь кардинального роста быстродействия в операциях глубокого обучения и некоторых других задачах.
|
Tesla A100 |
Tesla V100 |
Tesla P100 |
|
|
FP16 TFLOPS |
78 |
31,4 |
21,2 |
|
BF16 TFLOPS |
39 |
- |
- |
|
FP32 TFLOPS |
19,5 |
15,7 |
10,6 |
|
FP64 TFLOPS |
9,7 |
7,8 |
5,3 |
|
INT32 TOPS |
19,5 |
15,7 |
- |
|
FP16 Tensor TFLOPS + FP16 |
312/624* |
- |
- |
|
FP16 Tensor TFLOPS + FP32 |
312/624* |
- |
- |
|
BF16 Tensor TFLOPS + FP32 |
312/624* |
- |
- |
|
TF32 Tensor TFLOPS |
156/312* |
- |
- |
|
FP64 Tensor TFLOPS |
19,5 |
- |
- |
|
INT8 Tensor TOPS |
624/1248* |
- |
- |
|
INT4 Tensor TOPS |
1248/2496* |
- |
- |
Наглядной иллюстрацией к этому является сравнение NVIDIA A100 с прошлыми моделями семейства Tesla в задачах тренировки поискового алгоритма Google BERT и сценариях инференса.

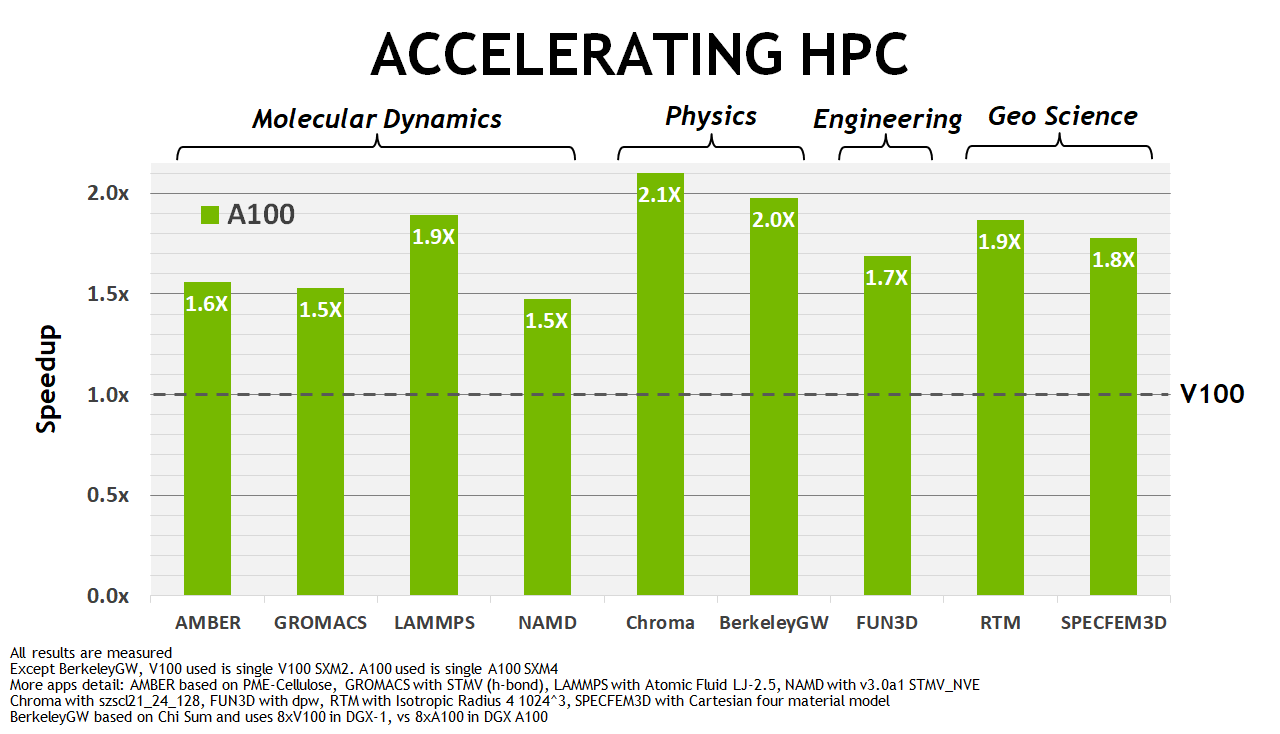
Также NVIDIA приводит сравнение A100 и V100 в ряде специализированных приложений из сферы HPC-вычислений. И тут мы видим преимущество нового ускорителя относительно Volta от полутора до двух раз.
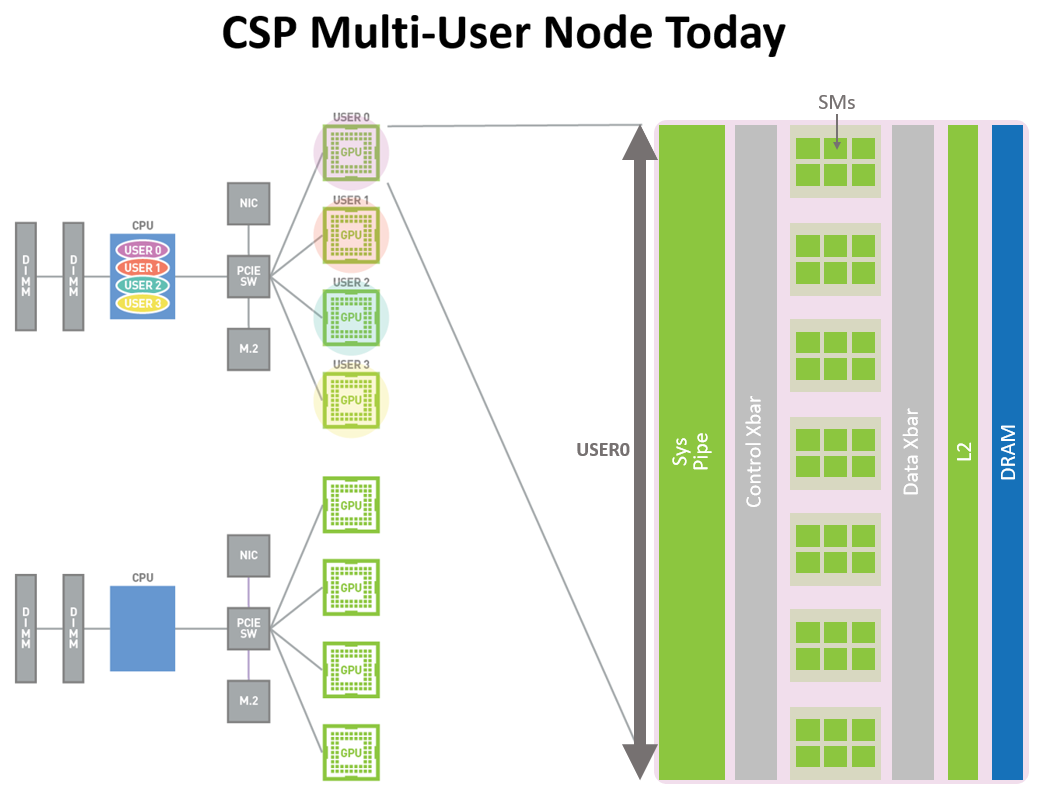
NVIDIA A100 предлагает новый метод распределении ресурсов для тех задач, что не требуют полной загрузки GPU. Технология виртуализации MIG (Multi-Instance GPU) позволяет разделить A100 на 7 виртуальных процессоров (по количеству активных кластеров). Если на Volta в случае выполнения нескольких приложений одно из них может мешать другим, используя больше ресурсов, то у Ampere будет семь независимых виртуальных процессоров с независимыми SM и своей областью памяти.
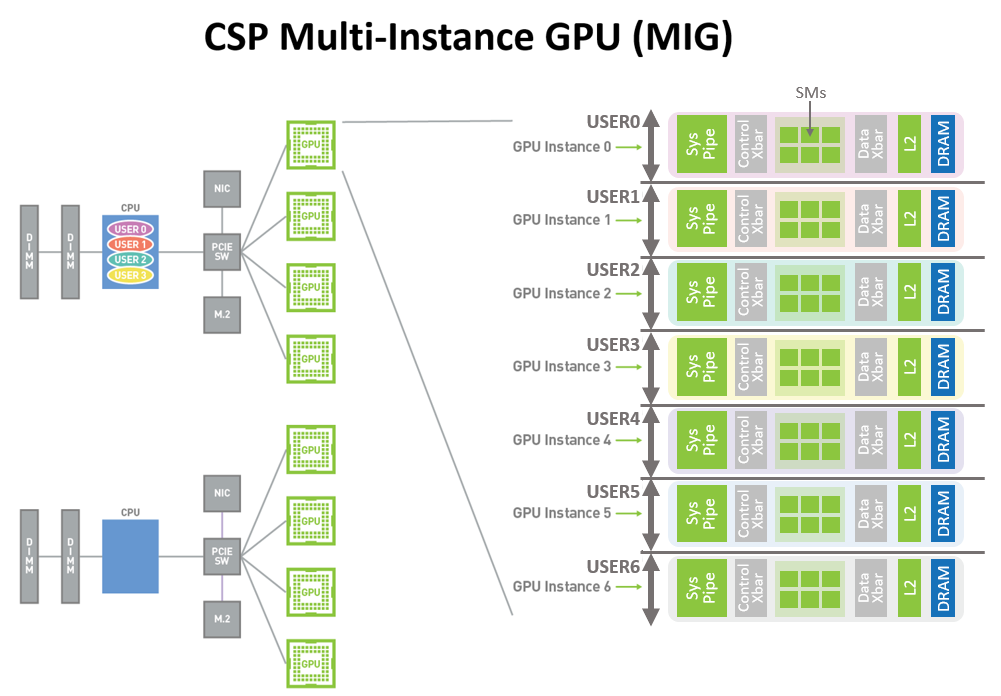
MIG позволяет организовать 7 виртуальных процессоров с изоляцией отказов для каждого клиент, и процессы не влияют друг на друга. Это реализуется на базе стандартной программной платформы CUDA, не требуя более сложных программных методов. А для более надежной работы MIG реализована новая технология определения ошибок и отказов, их изоляции и локализации.
Наряду с аппаратными улучшениями важную роль играет программная оптимизация. Для приложений с GPU-ускорением используется программная платформа параллельных вычислений CUDA. Вместе с новой архитектурой представлена обновленная программная платформа CUDA 11, которая позволяет использовать новые программные возможности тензорных ядер третьего поколения, Sparsity, MIG, новые особенности кэша L2 и прочие аппаратные особенности NVIDIA Ampere.
NVIDIA сразу представила готовые решения для центров обработки данных на базе новых ускорителей. Это вычислительные системы NVIDIA DGX A100 с восемью NVIDIA A100, которые обеспечивают производительность до 5 petaFLOPS в задачах ИИ. Передовая архитектура Ampere обеспечивают максимальную производительность такой системы. Построена она на базе платформы с двумя 64-ядерными процессорами AMD Rome, 1 ТБ памяти, накопителя SSD NVMe 15 ТБ, используется девять быстрых сетевых контроллеров Mellanox ConnectX-6 200 Gb/s.

Для работы нескольких ускорителей A100 существует две аппаратные платформы:
- HGX A100 8-GPU соединенные через NVSwitch
- HGX A100 4-GPU соединенные через NVLink

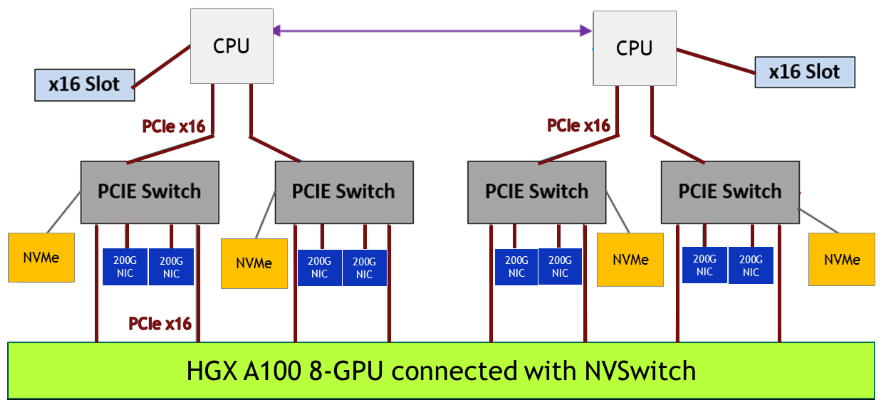
NVIDIA DGX A100 используют плату HGX A100 с узлами NVSwitch. Каждый процессор A100 имеет 12 портов NVLink, а каждый узел NVSwitch является переключателем, который связан со всеми восемью ускорителями A100. Такое соединение образует сетевую топологию, которая позволяет любому A100 взаимодействовать с другим A100 на плате с максимальной пропускной способностью шины NVLink 600 Гбайт/с

Структура серверной платформы с 8 ускорителями A100 показана на нижней блок-схеме.
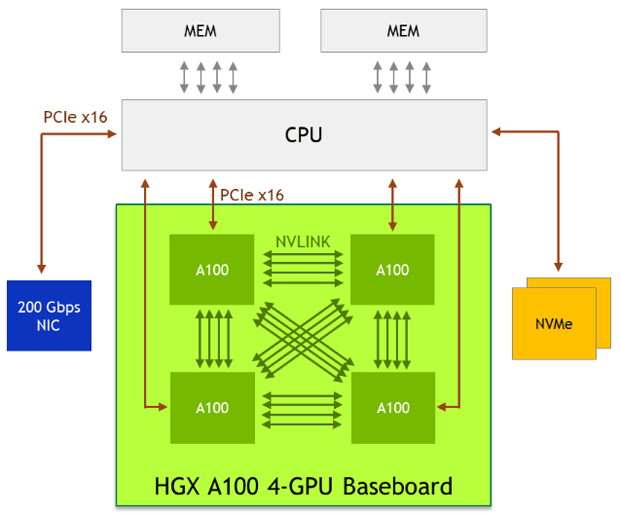
На плате GX A100 4-GPU соединение каждого A100 с другим A100 организована сразу через линии NVLink.
Системы NVIDIA DGX A100 будут задействованы в сервисах Alibaba Cloud, AWS, Baidu Cloud, Google Cloud, Microsoft Azure, Oracle и Tencent Cloud. Аппаратные серверные решения на базе A100 вскоре представят Atos, Dell Technologies, Fujitsu, GIGABYTE, H3C, HPE, Inspur, Lenovo, Quanta/QCT и Supermicro.
Подведем итоги. NVIDIA A100 —передовой ускоритель вычислений, который дает старт архитектуре Ampere. Это специализированное вычислительное устройство, основной сферой применения которого являются высокопроизводительные системы ИИ, что определяет архитектурные особенности и технические параметры данного устройства. При беглом взгляде на первый GPU Ampere можно выделить ключевые особенности, которые сохранятся и в процессорах игрового сегмента. Новая архитектура обладает улучшенными тензорными блоками и сильно прокачана в области смешенных вычислений. Будет очередное наращивание кэш-памяти в блоках SM и общего кэша L2. Топовые игровые Ampere могут сохранить новую структуру L2 для повышения пропускной способности кэша. На глобальном уровне сохранится знакомая кластерная структура и структура мультипроцессорных блоков SM. Но благодаря переходу на 7-нм техпроцесс у GeForce будет больше исполнительных блоков. Повышение рабочих частот если и будет, то у моделей среднего и бюджетного уровня. У A100 не оказалось ядер RT для ускорения операций при просчете трассировки лучей, но это не игровой продукт, поэтому в них необходимости. У старших игровых GPU эти блоки безусловно будут, и вероятно их производительность серьезно подтянут, что в сочетании с должной программной оптимизацией обеспечит серьезный рост производительности именно в трассировке лучей. А более высокая производительность тензорных блоков позволит улучшить алгоритмы DLSS с целью повышения качества картинки и производительности. Мы можем увидеть и новые технологии, завязанные на алгоритмы ИИ, которые не связаны непосредственно с графикой. К примеру, можно вспомнить недавно представленную технологию шумоподавления RTX Voice.