Компания NVIDIA начала год с анонса нового поколения видеокарт GeForce RTX 50-й серии на архитектуре Blackwell. Старшие модели GeForce RTX 5090 и GeForce RTX 5080 уже поступили в продажу, сегодня к ним присоединится GeForce RTX 5070 Ti, а в марте на рынок выйдет GeForce RTX 5070. Данное поколение уже вызвало определенные споры. С одной стороны — много новых революционных технологий, DLSS 4 с улучшенным масштабированием и генерацией до трех дополнительных кадров; с другой стороны — высокое энергопотребление, высокие цены и небольшое преимущество в обычных играх с растеризацией. Действительно, новая серия GeForce оказалось прорывной не во всем. Закон Мура сейчас серьезно замедлился, эволюция за счет освоения новых техпроцессов уже не работает, невозможно постоянно наращивать количество транзисторов и получать быстрые холодные видеокарты. И хотя инженеры NVIDIA постарались достичь лучшей энергоэффективности в новом поколении, главное преимущество архитектуры NVIDIA Blackwell в оптимизациях для нейронных нагрузок и тех перспективах, что она открывает для дальнейшего развития графики в играх.

Главные особенности архитектуры NVIDIA Blackwell
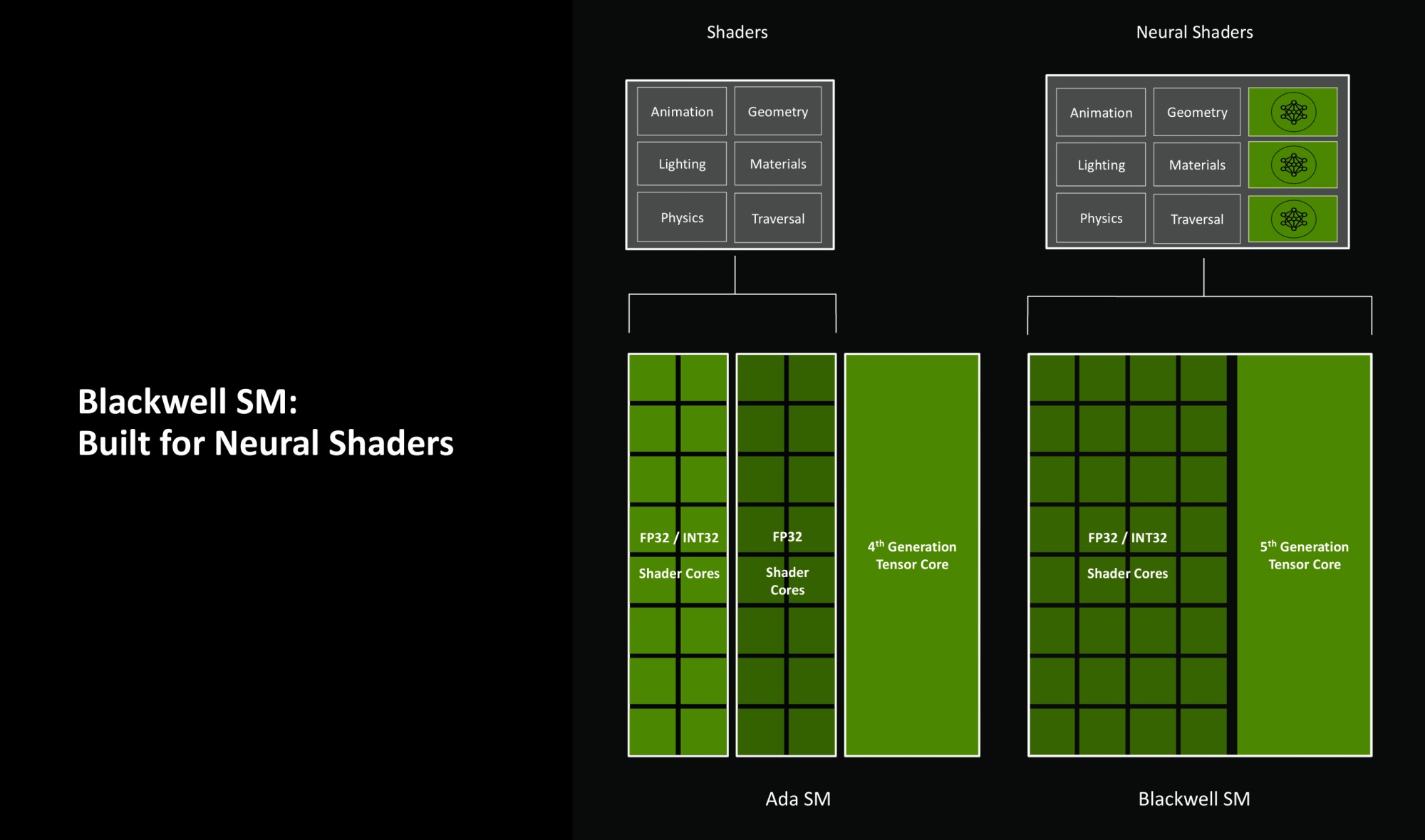
- Новые функции в SM и вычислительных ядрах для нейронных шейдеров, в том числе удвоение пропускной способности целочисленных вычислений за такт
- Новые функции Max-Q для лучшей энергоэффективности и более тонкого управления питанием разных блоков GPU
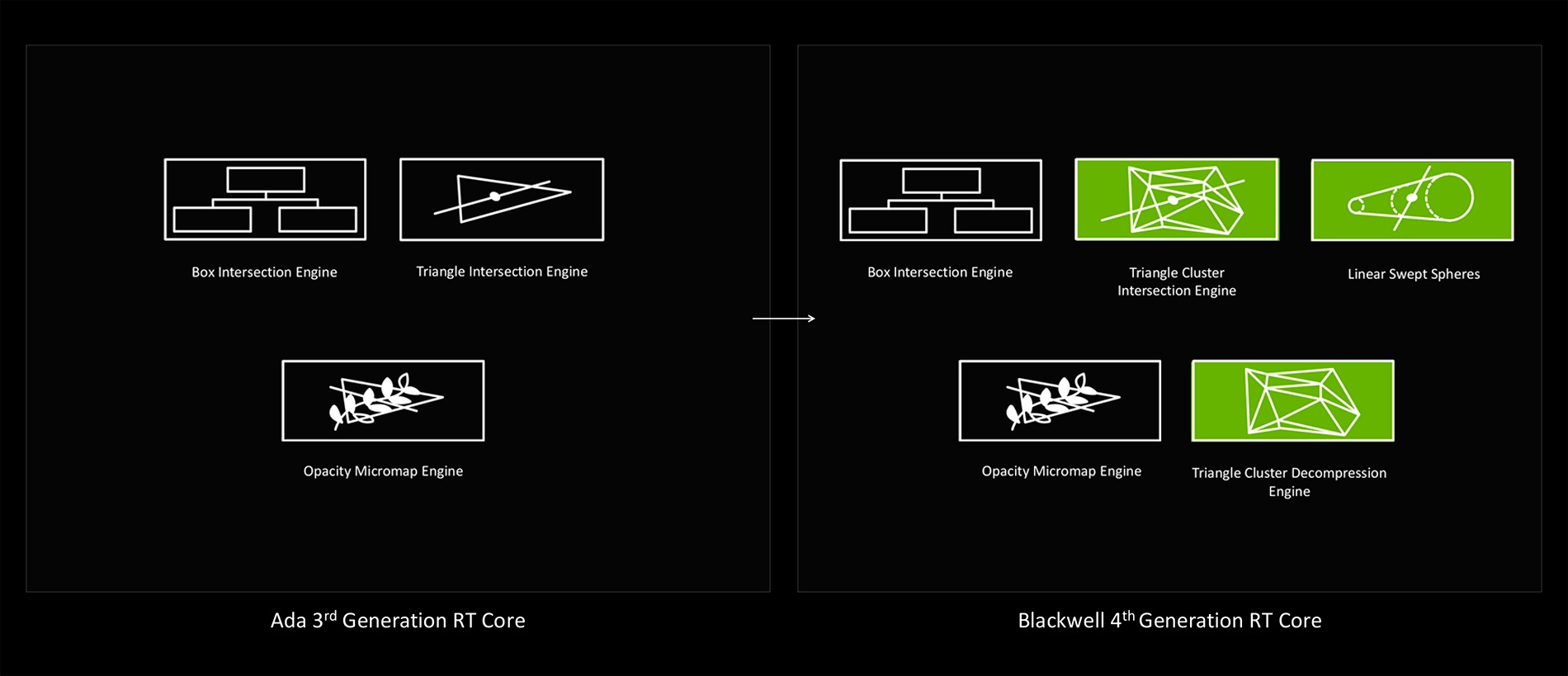
- Новые ядра RT 4-го поколения для трассировки лучей и нейронного рендеринга
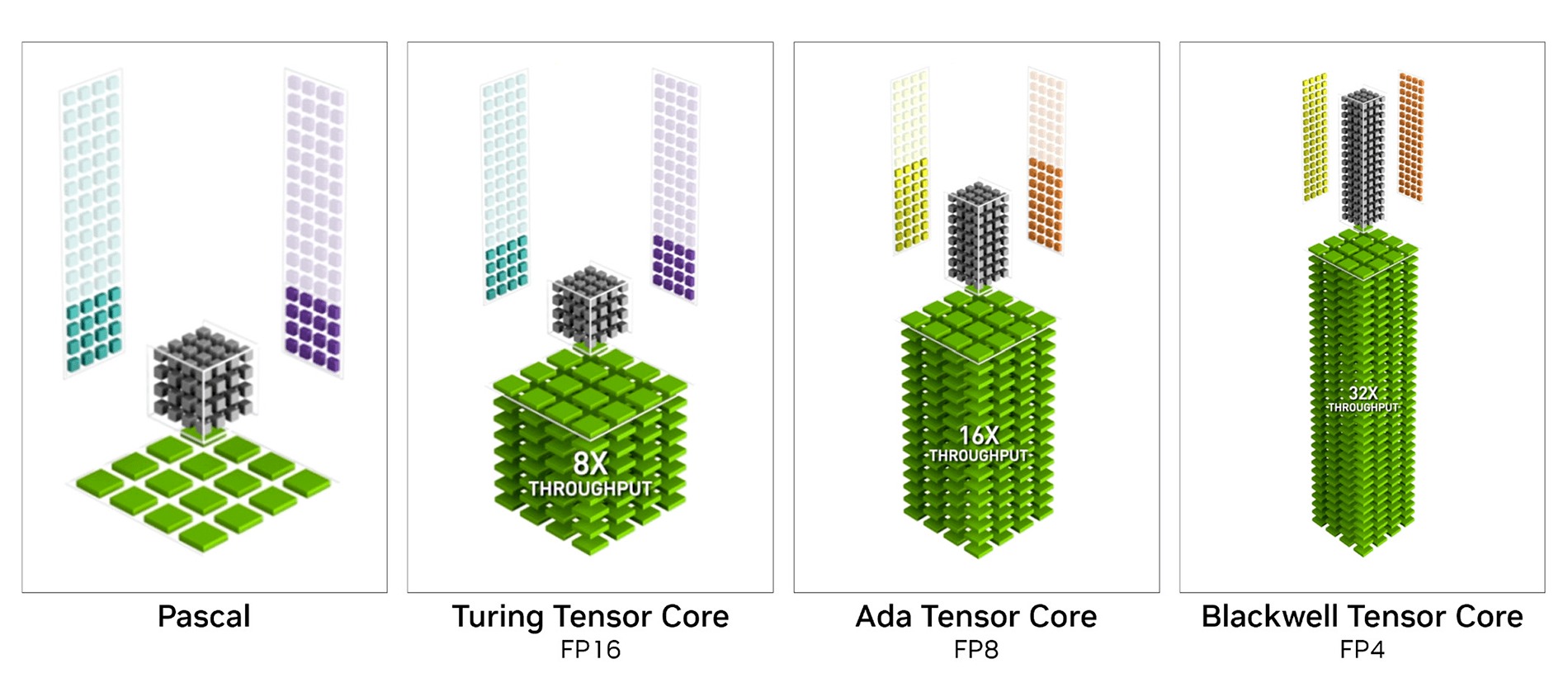
- Новые тензорные ядра 5-го поколения с повышенной производительностью и поддержкой новых типов вычислений FP4
- Новая технология DLSS 4 с многокадровой генерацией
- Нейронные шейдеры — новый тип шейдеров, который открывает новую эру графических инноваций
- AI Management Processor — дополнительный сопроцессор для управления задачами ИИ
- Новая скоростная память GDDR7 с высокой пропускной способностью
- Технология RTX Mega Geometry направленная на увеличение геометрии в сценах с трассировкой лучей
Все видеокарты получили обновленные блоки кодирования/декодирования видео. Улучшен механизм управления Boost. Также новое поколение поддерживает интерфейс PCI Express 5.0. Обо всем этом мы расскажем ниже.

На данный момент анонсировано четыре видеокарты — GeForce RTX 5090, RTX 5080, RTX 5070 Ti и RTX 5070.
Архитектура NVIDIA Blackwell и GPU GB202
Новая архитектура получила название в честь американского математика Дэвида Гарольда Блэквелла, известного работами в области математической статистики. Рассмотрим основные архитектурные изменения на примере старшего графического процессора GB202, который лег в основу флагмана GeForce RTX 5090. Это очень большой и сложный чип, который насчитывает 92 миллиарда транзисторов. Изготовляется он на заводах TSMC по техпроцессу 4N, который является специальной оптимизированной версией технологии 5 нм. На этом же техпроцессе выпускалось и прошлое поколение GPU Ada Lovelace для GeForce RTX 40. При этом плотность транзисторов у нового GPU составляет 122,9 миллиона на кв. мм, а у предшественника 125,3 миллиона на кв. мм.
Общая структура GB202 напоминает прошлый чип AD102. Это 12 кластеров GPC, один из которых у GeForce RTX 5090 деактивирован. Традиционно процессор идет с частично отключенными блоками, что позволяет использовать кристаллы с небольшими дефектами и повышает общий процент пригодных к использованию чипов. На уровне глобального управления потоками кроме GigaThread Engine появился AI Management Processor. Также у графического процессора есть Optical Flow Engine, который внедрили в прошлом поколении.
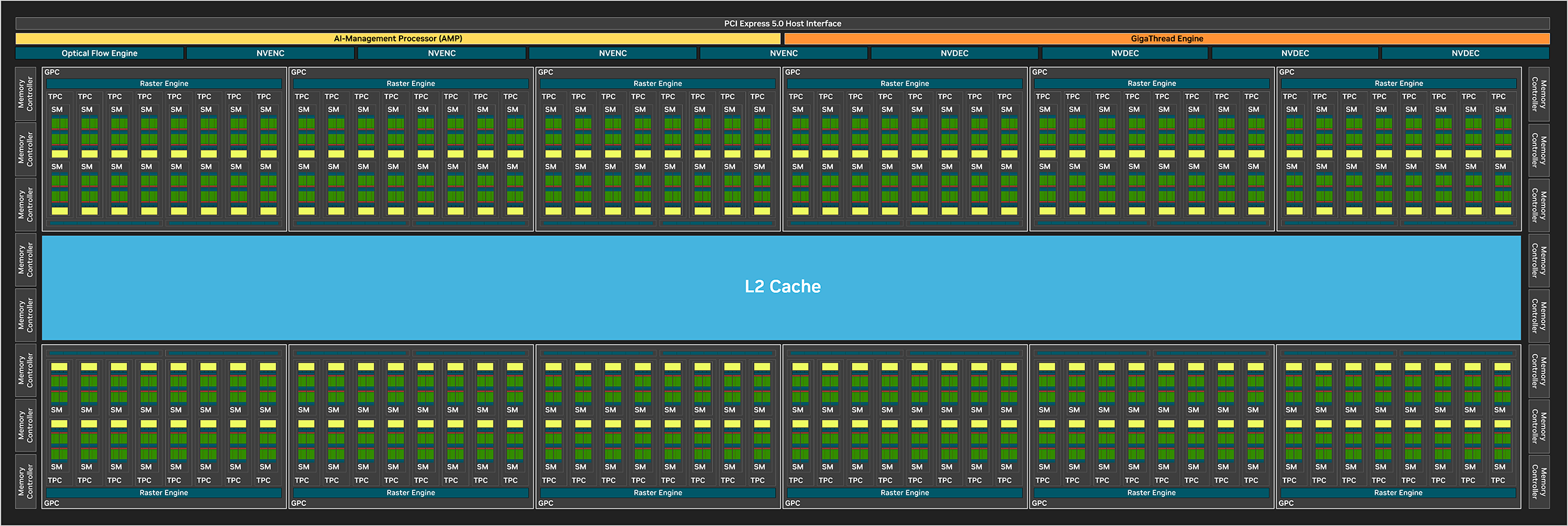
Кластер GPC является основным высокоуровневым блоком во всех графических процессорах NVIDIA. Внутри одного кластера 8 блоков TPC и разделенный на два раздела движок растеризации по 8 блоков ROP в каждом. Каждый TPC содержит два мультипроцессора SM с основными вычислительными ядрами и PolyMorph Engine.
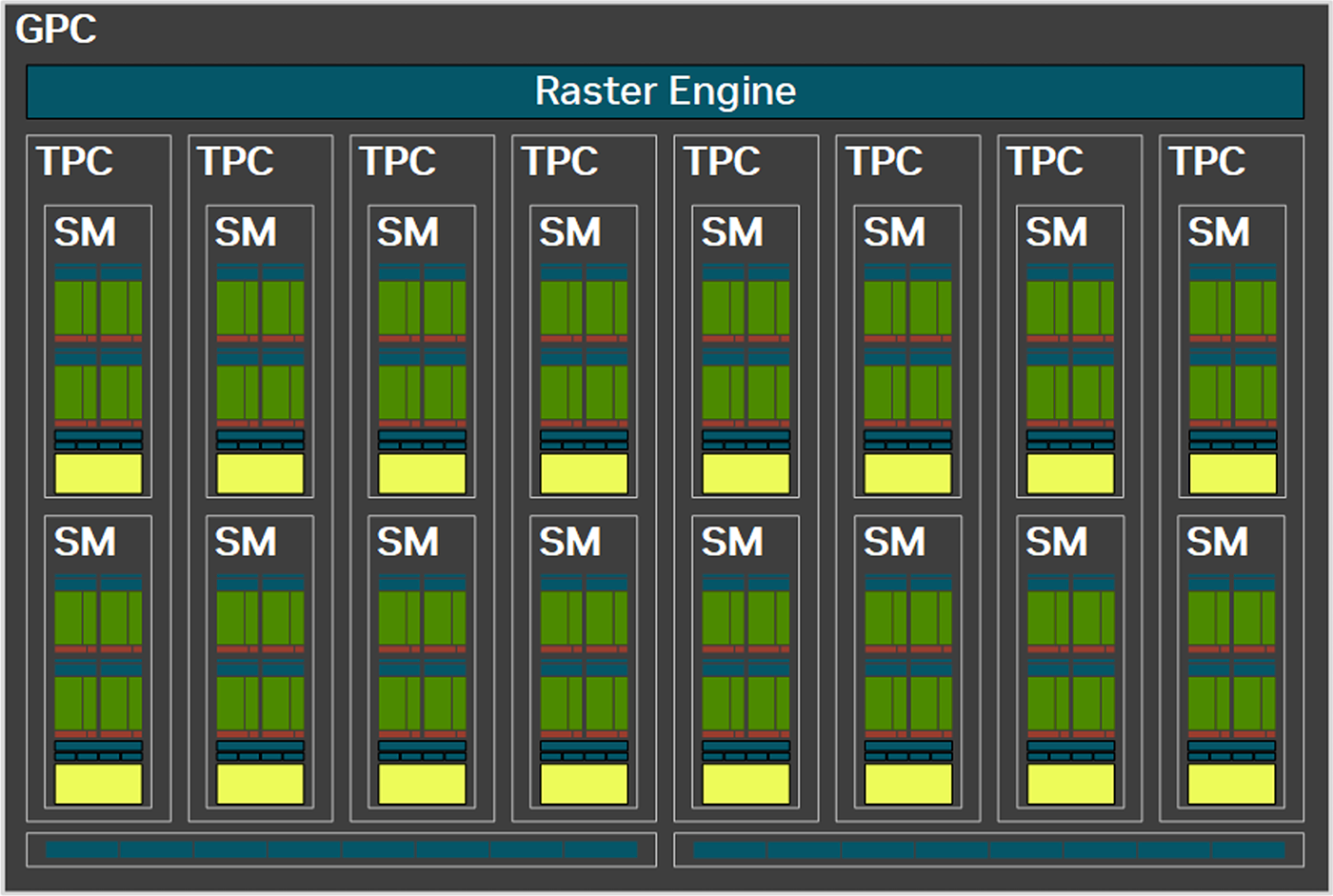
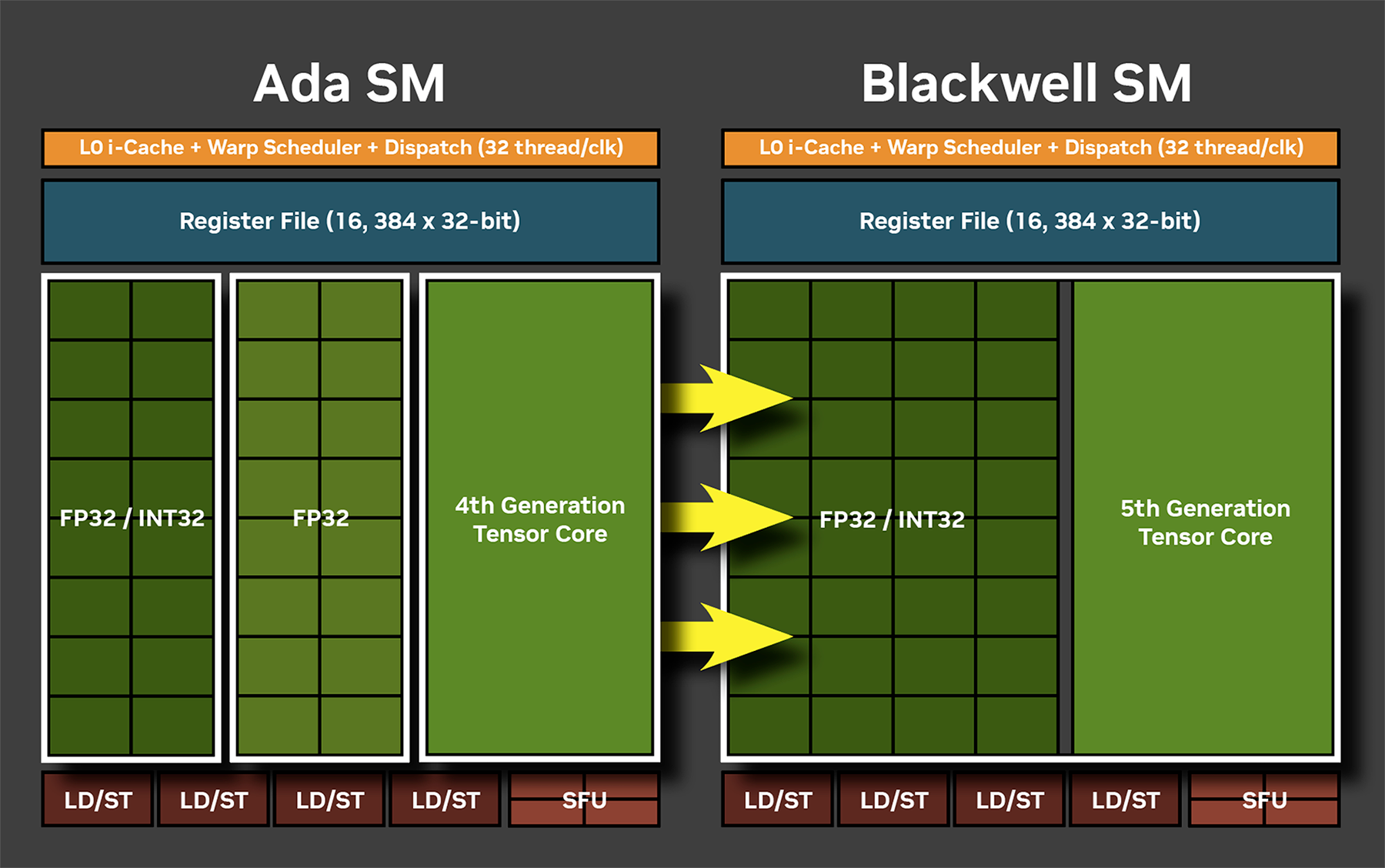
SM является главным компонентом архитектуры, играя основную роль в параллельной обработке. Каждый SM содержит 128 ядер CUDA, которые организованы в четыре группы со своими текстурными блоками, тензорными блоками и регистрами, плюс кэш L1 и планировщик с диспетчером потоков у каждой из 4 групп. Каждый SM содержит новое мощное ядро RT для операций трассировки.

Ядра CUDA стали более универсальными. Они могут работать как в режиме FP32, так и в INT32 в рамках одного тактового цикла. В прошлом поколении лишь половина ядер могла работать в INT32. Благодаря этому пропускная способность в режиме INT32 выросла вдвое. Современные GPU комбинируют разные типы нагрузок, и эта универсальность является ответом на востребованность разных типов вычислений.
Полная конфигурация GB202 насчитывает 192 SM, 24576 ядра CUDA, 192 ядра RT, 768 тензорных блока и 768 текстурных блока, плюс кэш L2 объемом в 128 МБ. Но для GeForce RTX 5090 идет вариант со 170 активными SM, что дает 21760 ядер CUDA, 680 тензорных ядер, 170 ядер RT и 680 текстурных ядер. И это почти на 33% больше количества вычислительных блоков у GeForce RTX 4090. Но обе видеокарты сохранили 176 ROP. Каждый SM по-прежнему оснащен 128 КБ кэш-памяти L1, а общий кэш L2 у RTX 5090 96 МБ вместо 72 МБ у RTX 4090.
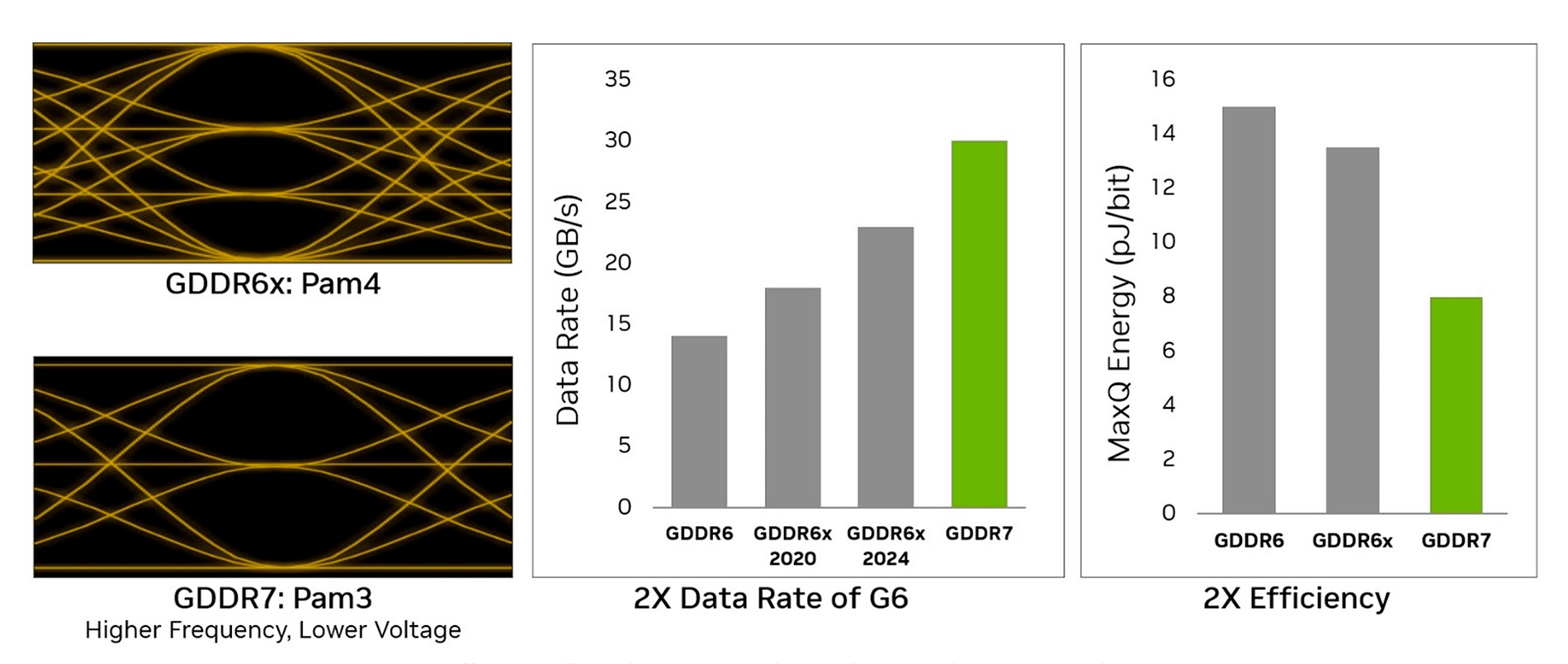
Процессор GB202 получил 16 32-битных контроллера памяти, что обеспечивает передачу данных по общей шине разрядностью 512 бит. Это же позволило оснастить GeForce RTX 5090 рекордным объем видеопамяти в 32 ГБ. Все новые видеокарты перешли на память GDDR7. Это новый стандарт памяти с технологией импульсно-амплитудной модуляции PAM3 с тремя уровнями сигнала, что позволяет кодировать 1,5 бита за такт. В памяти GDDR6X использовался метод PAM4, но повышение частоты упиралось в шум и дополнительные сложности в передаче сигнала. GDDR7 является компромиссным вариантом благодаря переработанной архитектуре тактирования и улучшенной подготовке ввода-вывода, плюс лучшая энергоэффективность. В итоге модули памяти GDDR7 у GeForce RTX 5090 обеспечивают скорость передачи сигнала 28000 Гбит/с при общей пропускной способности видеокарты 1792 ГБ/с. Для GeForce RTX 5080 используется еще более быстрая память 30000 Гбит/с, но в сочетании с шиной 256 бит.
Графические процессоры Blackwell получили улучшенные энергосберегающие механизмы и более гибкое управление Boost-частотами. При этом заявленное значение Boost Clock на 100 МГц ниже, чем у старого флагмана — 2407 МГц. Общая мощность видеокарты выросла до рекордных 575 Вт.
Для наглядности все данные по характеристикам GeForce RTX 5090 приведены вместе с параметрами старых флагманских моделей в одной таблице.
Характеристики GeForce RTX 5090
|
GeForce RTX 5090 |
GeForce RTX 4090 |
GeForce RTX 3090 Ti |
GeForce RTX 3090 |
GeForce RTX 2080 Ti |
|
|
Архитектура |
Blackwell |
Ada Lovelace |
Ampere |
Ampere |
Turing |
|
Ядро |
GB202 |
AD102 |
GA102 |
GA102 |
TU102 |
|
Техпроцесс, нм |
TSMC 4N (5 нм) |
TSMC 4N (5 нм) |
Samsung 8N |
Samsung 8N |
TSMC 12FFN |
|
Количество транзисторов, млн. шт |
92200 |
76300 |
28300 |
28300 |
18600 |
|
Площадь ядра, кв. мм |
750 (761,56) |
609 |
628 |
628 |
754 |
|
GPC |
11 |
11 |
7 |
8 |
6 |
|
TPC |
85 |
64 |
41 |
41 |
36 |
|
SM |
170 |
128 |
84 |
82 |
68 |
|
CUDA-ядра |
21760 |
16384 |
10752 |
10496 |
4352 |
|
Тензорные ядра |
680 (5-е поколение) |
512 (4-е поколение) |
336 (3-е поколение) |
328 (3-е поколение) |
544 (2-е поколение) |
|
Ядра RT |
170 (4-е поколение) |
128 (3-е поколение) |
84 (2-е поколение) |
82 (2-е поколение) |
68 (1-е поколение) |
|
Текстурные блоки TMU |
680 |
512 |
336 |
328 |
272 |
|
Блоки растеризации ROP |
176 |
176 |
112 |
112 |
88 |
|
FP32 FLOPS |
104,8 |
82,6 |
40 |
35,6 |
13,4 |
|
Tensor TOPS FP16 |
838 (3352 FP4) |
661 (1321 FP8) |
320 |
285 |
108 |
|
RT FLOPS |
317,5 |
191 |
84 |
69,5 |
69,5 |
|
L2 кэш |
96 МБ |
72 МБ |
6 МБ |
6 МБ |
5,5 MB |
|
Частота ядра (Base Clock), МГц |
2017 |
2235 |
1560 |
1395 |
1350 |
|
Частота ядра (Boost Clock), МГц |
2407 |
2520 |
1860 |
1695 |
1695 |
|
Шина памяти, бит |
512 |
384 |
384 |
384 |
384 |
|
Тип памяти |
GDDR7 |
GDDR6X |
GDDR6X |
GDDR6X |
GDDR6 |
|
Частота памяти (Data rate) |
28000 Гбит/с |
21000 Гбит/с |
21000 Гбит/с |
19500 Гбит/с |
14000 Гбит/с |
|
Объём памяти, ГБ |
32 |
24 |
24 |
24 |
11 |
|
ПСП памяти |
1792 ГБ/с |
1008 ГБ/с |
1008 ГБ/с |
936 ГБ/с |
616 ГБ/с |
|
Интерфейс |
PCI-E 5.0 |
PCI-E 4.0 |
PCI-E 4.0 |
PCI-E 4.0 |
PCI-E 4.0 |
|
Мощность TDP, Вт |
575 |
450 |
450 |
350 |
250 |
При беглом взгляде самые серьезные изменения заметны в подсистеме памяти. Но внутри вычислительных блоков тоже присутствуют есть важные изменения.
Тензорные ядра 5-го поколения
Blackwell использует тензорные ядра 5-го поколения. Впервые эти аппаратные блоки появились в специализированных ускорителях вычислений Volta в 2017 году, а второе поколение было внедрено в видеокарты Turing (GeForce RTX 20), где также впервые появились и ядра для ускорения рейтрейсинга. Первые тензорные ядра были рассчитаны на операции умножения матриц в формате FP16. Но по мере совершенствования и развития машинного обучения совершенствовались и эти блоки, получая поддержку новых востребованных форматов для ускорения общего потока вычислений. В Blackwell добавлена поддержка операций FP4 и FP6, а также новый FP8 Transformer Engine второго поколения, аналогичный тому, что используется в GPU для центров обработки данных. Новые форматы позволяют использовать более низкий уровень квантования, уменьшая размеры моделей ИИ и повышая скорость расчетов. И благодаря внедрению FP4 компания NVIDIA заявляет о совокупной пиковой производительности в операциях ИИ до 3352 TOPS (триллион операций в секунду). Для сравнения, GeForce RTX 4090 в FP8 обеспечивает 1321 TOPS. При работе в формате FP16 пиковые показатели этих же видеокарт 838 и 661 TOPS соответственно.
RT-ядра 4-го поколения
Blackwell использует ядра RT 4-го поколения, которые стали еще мощнее и получили некоторые новые функции. Они содержат вычислительные блоки для ускорения основного алгоритма Bounding Volume Hierarchy (BVH), Ray-Triangle Intersection для просчета пересечения луча с треугольником и ограничивающим прямоугольником. Также RT получил Opacity Micromap Engine для оптимизации просчета геометрии и работы новой технологии RTX Mega Geometry. Плюс Triangle Cluster Compression Engine для оптимизации работы с геометрией и Linear Swept Spheres для ускорения трассировки для тонкой геометрии, например, для шерсти и волос.
RTX Mega Geometry
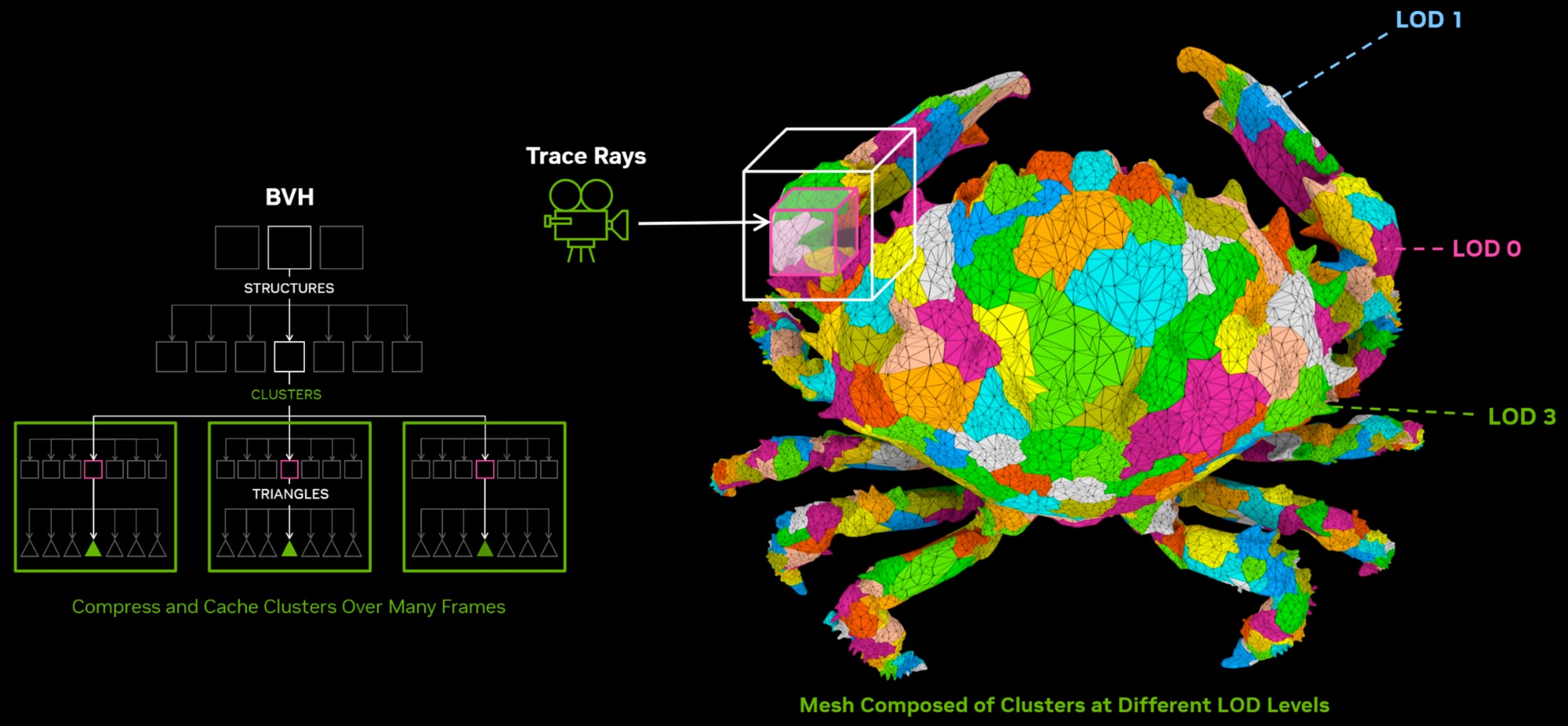
Технология RTX Mega Geometry является одним из важных нововведений, она позволяет выполнять сложную трассировку современным движкам с большим уровнем детализации, например, для Unreal Engine 5 с Nanite. Это оптимизирует обработку сложных сцен и позволит повысить качество теней, отражений и непрямого освещения. Современные движки используют кластерную систему загрузки для изменения LOD, что требует частого изменения сетки геометрии при просчете иерархии BVH для трассировки. В режиме реального времени при сложной геометрии это создает невероятно высокую нагрузку. Mega Geometry оптимизирует процесс, работая с кластерами треугольников в качестве первоначальных примитивов, а потом использует эти данные для построения конечной более детальной структуры BVH. Также GPU лучше управляет всем процессом, минимизируя обращения к CPU.
Специально для сверхсложных сцен предлагается вариант Mega Geometry со структурами Partitioned Top Level Acceleration Structure, где оптимизация базируется на факте того, что большинство объектов в сцене статичны от одного кадра к другому. Это позволяет работать со статичными и динамичными секторами кадра.
Также Mega Geometry позволяет реализовать и другие механизмы ускорения трассировки для геометрических методов — например, ускорение обработки поверхностей с иерархическим разбиением (Subdivision Surfaces).
Mega Geometry состоит из новых расширений API RTX, определенных оптимизаций в ядрах RT Blackwell и на уровне драйвера. Новые функции и структуры PTLAS поддерживаются в наборе инструкций DirectX 12 (DXR), Vulkan и OptiX 9.0. А новые тензорные ядра специально проектированы для Mega Geometry.
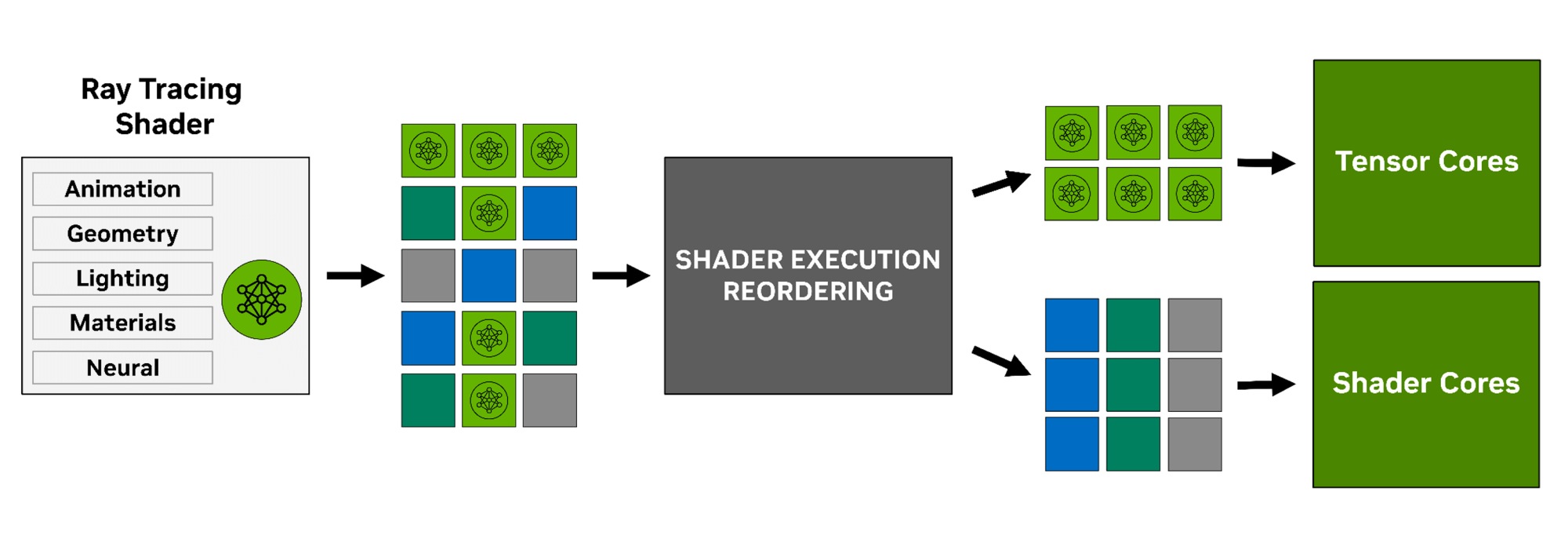
Shader Execution Reordering
В архитектуре Blackwell улучшены механизмы Shader Execution Reordering (SER), что впервые внедрены в Ada Lovelace. SER 2.0 улучшает распределение вычислительных потоков для максимальной загрузки GPU в приложениях с разным типом нагрузок, включая более эффективное распределение задач для тензорных ядер. Упоминается, что новая логика SER работает в два раза эффективнее.
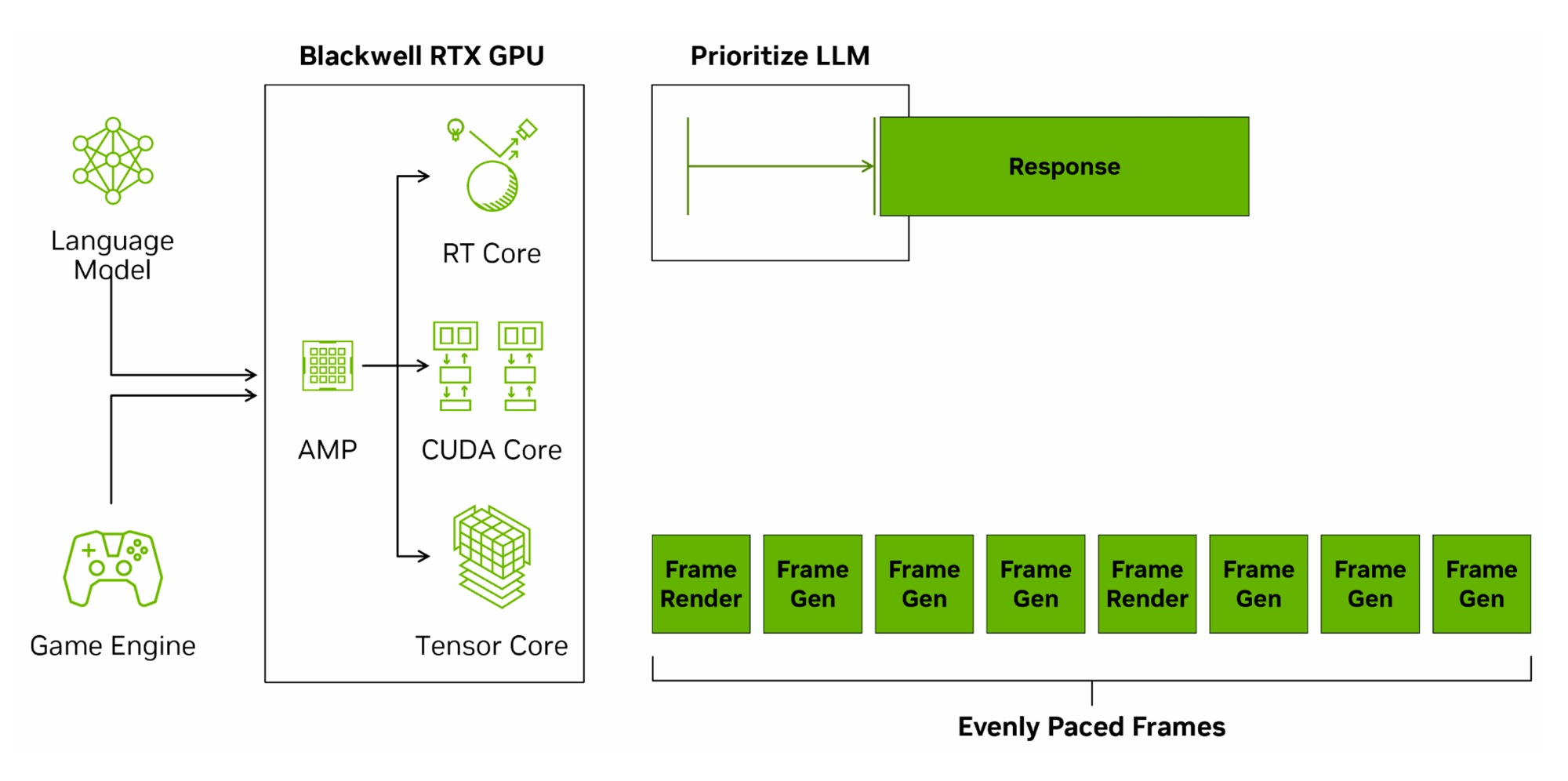
AI Management Processor
Выше мы упоминали о внедрении AI Management Processor (AMP). Это программируемых планировщик для более эффективного управления разным типом нагрузок в масштабах всего GPU. Аппаратно он реализован в виде отдельного сопроцессора RISC-V, обеспечивая более быстрое планирование контекстов графического процессора с меньшей задержкой, чем предыдущие методы. AMP берет на себя часть задач планирования, которые ранее выполнялись на CPU. Такое разрешение GPU управлять собственной очередью задач может привести к меньшей задержке из-за снижения количества двусторонних коммуникаций между графическим процессором и центральным процессором. Это улучшает многозадачность при работе нескольких приложений, а и в играх может обеспечить более плавную частоту кадров.
Улучшенный кодировщик NVENC и вывод видео
Серьезные изменения в блоках кодирования/декодирования видео. Все прошлые GeForce поддерживали стандарт кодирования цвета 4:2:0. Blackwell поддерживает цветовую субдискретизацию 4:2:2, что ранее было доступно лишь в профессиональных решениях. Вместо хранения цвета в виде значений красного, зеленого и синего (RGB), цвет сохраняется как яркость (Y), синяя разница цветности (U) и красная разница цветности (V). Формат кодирования YUV 4:4:4 требует большой пропускной способности, а файлы занимают больший объем. Формат используется в профессиональной среде, в том числе он распространен в профессиональных камерах. Такое кодирование полезно для контента HDR и для сохранения мелких деталей на видео.
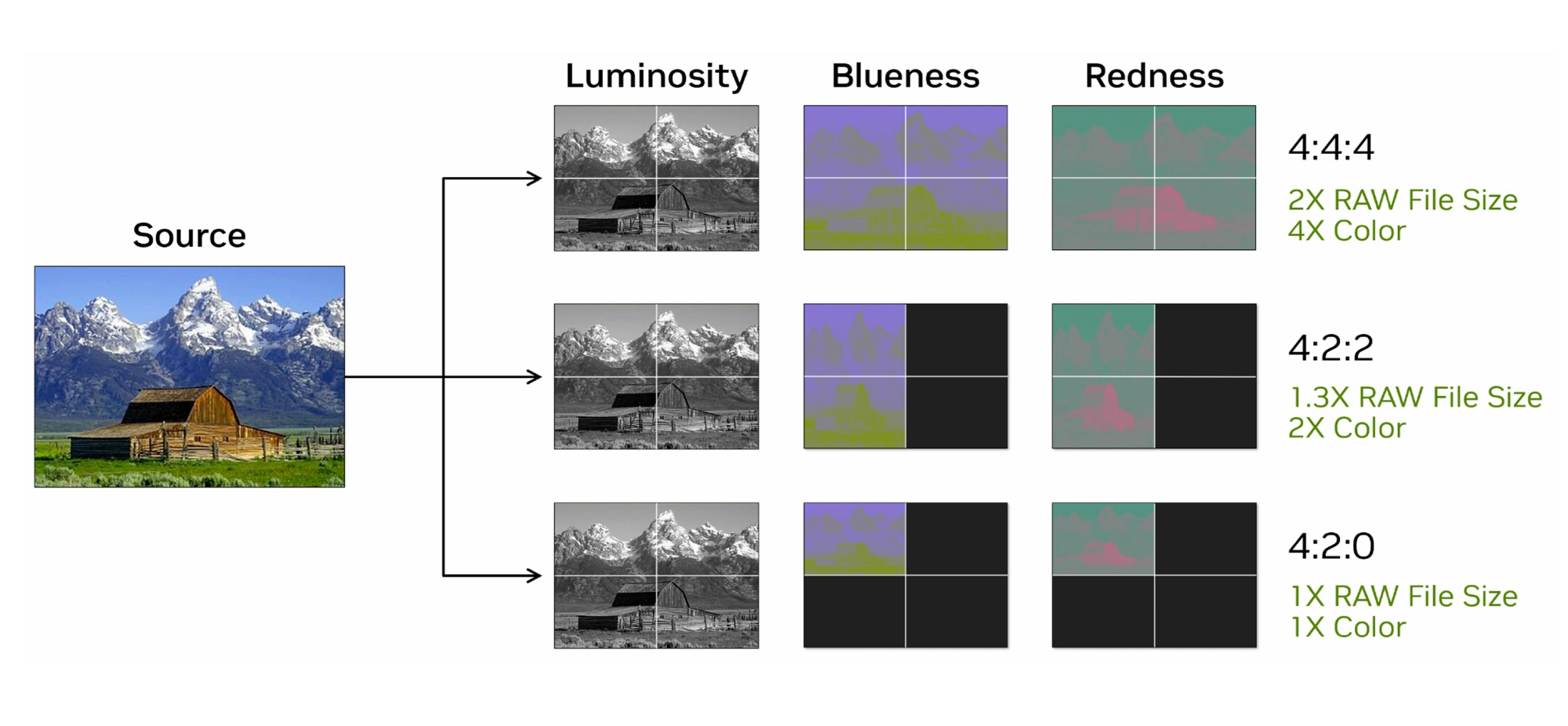
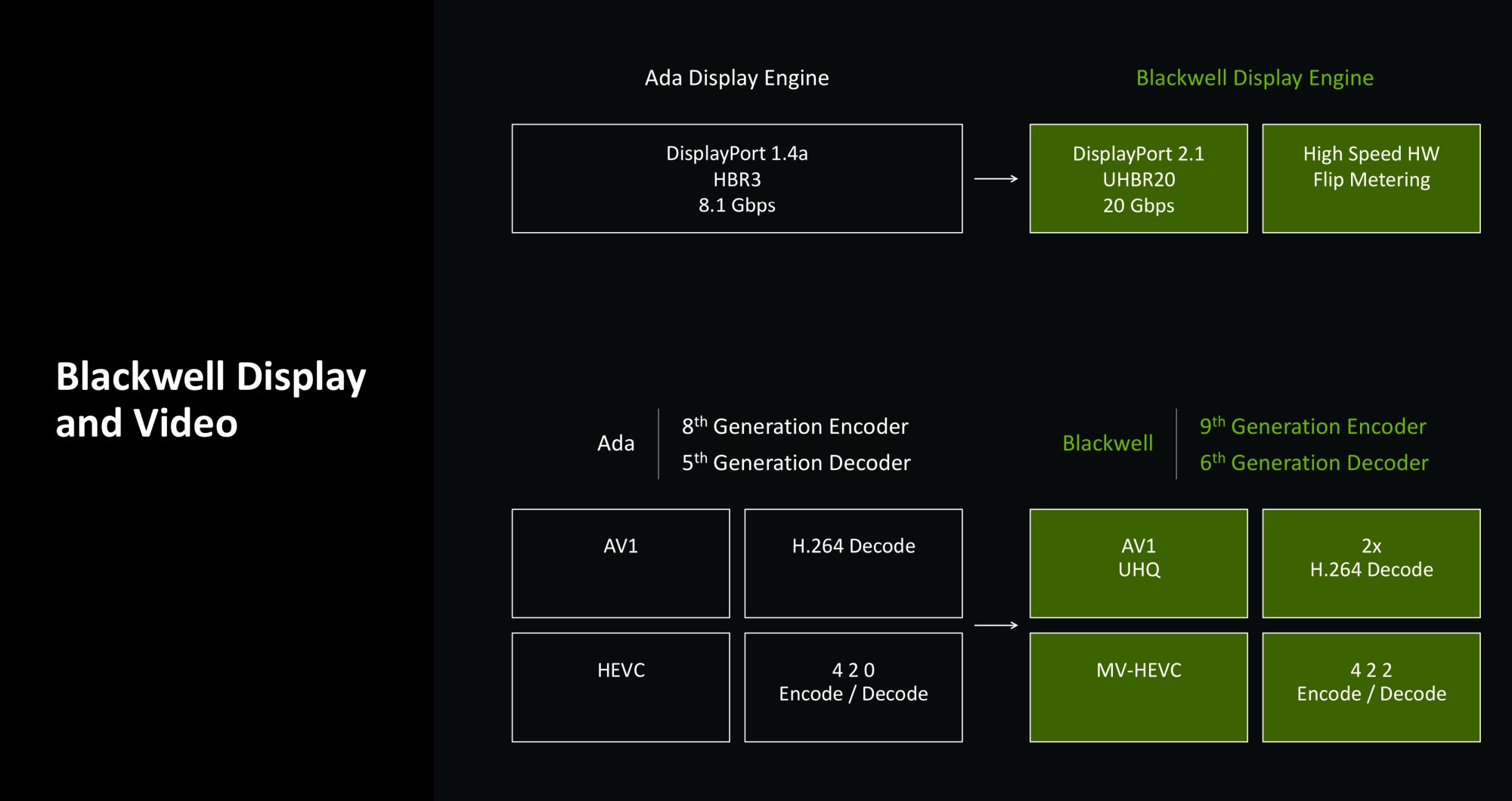
Обновлены блоки NVENC для аппаратного кодирования видео обновлены до 9-го поколение. Кроме нового цветового формата они также предложат улучшение качества работы с AV1 и HEVC на 5%, поддержку нового режима AV1 Ultra High Quality (UHQ). Аппаратные декодеры NVENC обновлены до 6-го поколения, предлагая полную поддержку H.264 и HEVC 4:2:2 и повышение скорости работы с H.264. При этом GeForce RTX 5090 насчитывает три кодера и два декодера, ускоряя обработку видео.
Разница в скорости экспорта видео может быть до четырёх раз, если сравнивать с GeForce RTX 3090, который имеет один кодировщик.
|
|
GeForce RTX 5090 |
GeForce RTX 4090 |
GeForce RTX 3090 |
|
Аппаратный кодировщик видео |
3 x NVENC (9th Gen) |
2 x NVENC (8th Gen) |
1 x NVENC (7th Gen) |
|
Аппаратный декодер видео |
2 x NVDEC (6th Gen) |
1 x NVDEC (5th Gen |
1 x NVDEC (5th Gen) |
Видеокарты оснащены DisplayPort 2.1b с пропускной способность до 80 Гбит/с и поддержкой режима передачи UHBR 20 (сверхвысокая скорость данных 20 Гбит/с на линию). DisplayPort 2.1b UHBR 20 позволяет запускать дисплеи с высоким разрешением, используя максимально возможные частоты обновления: 8K (7680x4320) @ 165 Гц (требуется DSC) и 4K (3840x2160) @ 480 Гц (требуется DSC). Для высоких скоростей соединения требуется сертифицированный кабель DP80LL.
Управление питание и улучшения Max-Q
Архитектура Blackwell получила важные улучшения в наборе технологий Max-Q, включая изменения в механизмах управлением питания и переключением частот. Плюс энергоэффективный режим работы памяти GDDR7, быстрая отзывчивость при переходе в режим сна и технология DLSS 4, которая «экономит» ресурсы чипа, генерируя дополнительные кадры.

Это первое столь серьезное изменения в архитектуре NVIDIA за 10 лет. Новая система управления питанием позволяет раздельно регулировать напряжения в разных сегментах чипа и отключать их в моменты небольшого простоя, экономя энергию. Это снижает общее энергопотребление чипа в режиме ожидания и при невысокой изменчивой нагрузке. И это крайне важно для мобильных GPU, особенно при работе от аккумулятора.
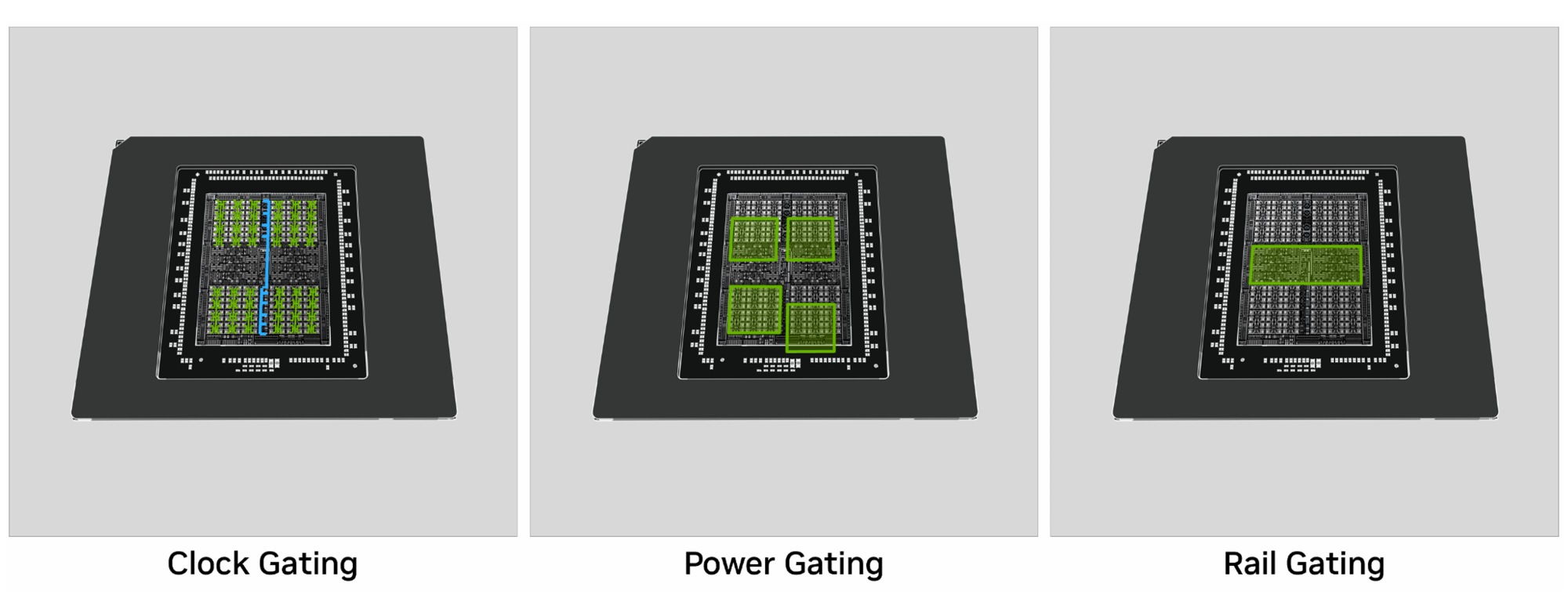
Чип быстрее переключается в состояние с низким потреблением энергии. Blackwell в 10 раз быстрее входит в состояние глубокого сна чем Ada, что позволяет значительно экономить энергию в состоянии сна с самым низким энергопотреблением, обеспечивая дополнительную экономии энергии.
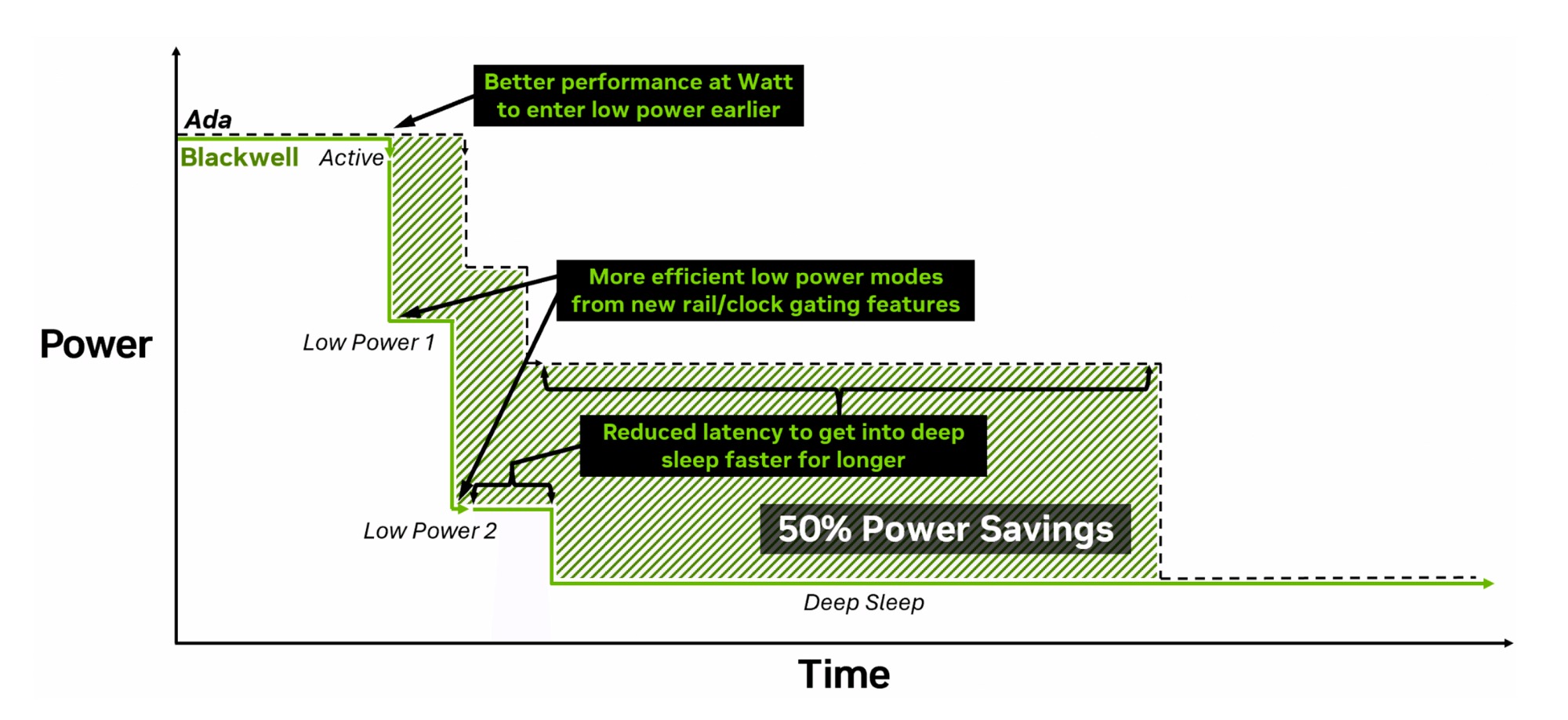
Ускорен механизм переключения частот. Теперь частоты GPU переключаются в 1000 раз быстрее, чем в прошлых поколениях. Благодаря этому Blackwell быстрее реагирует на изменчивые динамические нагрузки, повышая или понижая таковую частоту. Это позволяет лучше раскрыть весь потенциал GPU в рамках заданного лимита мощности и быстрее переходить в энергосберегающие режимы при низкой нагрузке.

DLSS 4 и Multi Frame Generation
Набор технологий DLSS развивается уже несколько лет. С момента запуска DLSS в 2018 году было несколько важных обновлений. В состав DLSS сейчас входит технология масштабирования DLSS Super Resolution (SR), а также Ray Reconstruction и Frame Generation, которые появились вместе с GeForce RTX 40-й серии в третьем поколении DLSS. Теперь все они получают важное обновление благодаря переходу на новую модель ИИ для построения изображения.
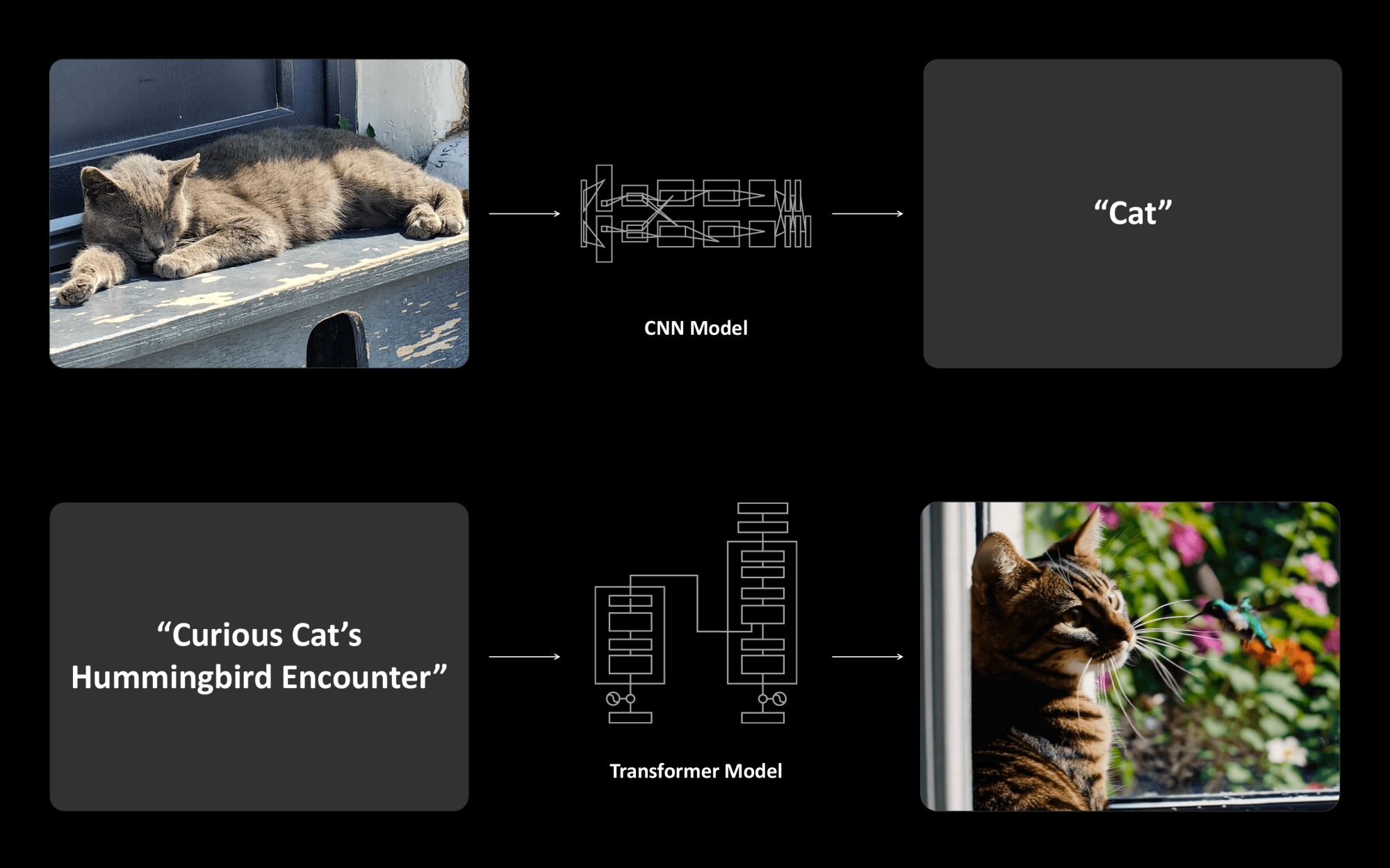
Ранее NVIDIA использовала сверточные нейронные сети CNN для пиксельных данных. При этом шло постоянное обучение и совершенствование алгоритмов масштабирования, что было хорошо видно по эволюции от первых версий DLSS до DLSS 3.8. Теперь будет использоваться модель-трансформер (Transformer), которая лучше работает с последовательностями данных.
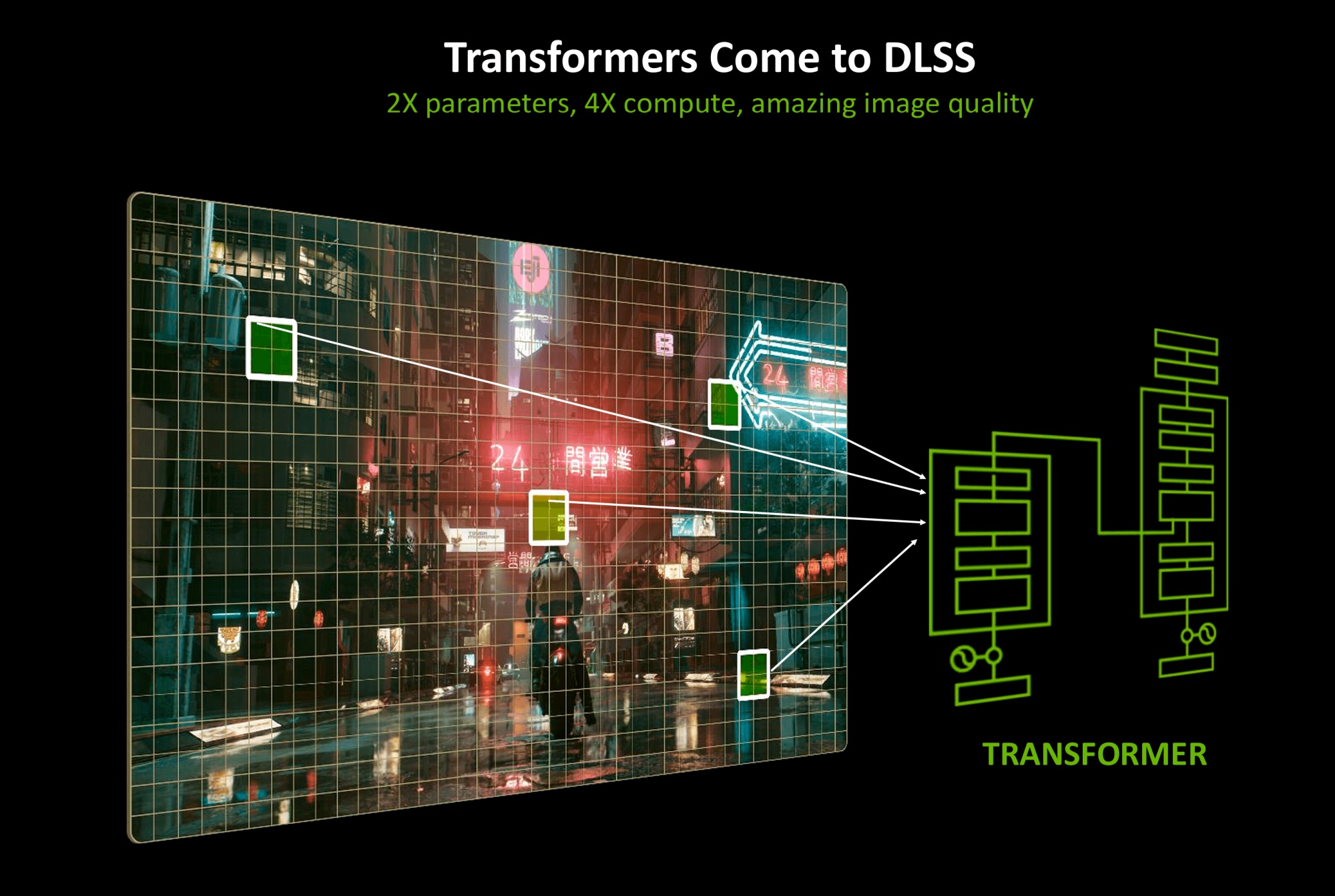
Благодаря этому улучшено качество изображения Super Resolution и стабильность картинки в динамике — картинка четче, меньше ореолов, мерцаний и других привычных артефактов. Transformer обеспечит и лучшее качество изображения при сглаживании DLAA. Также будут визуальные улучшения в работе технологии Ray Reconstruction, которая улучшает отображение сцен со сложным освещением для шумоподавления при интенсивной трассировке.


Продвинутая ИИ-модель Transformer позволила NVIDIA внедрить новую технологию многокадровой генерации Multi Frame Generation (MFG). Технология может создавать до трех дополнительных кадров.
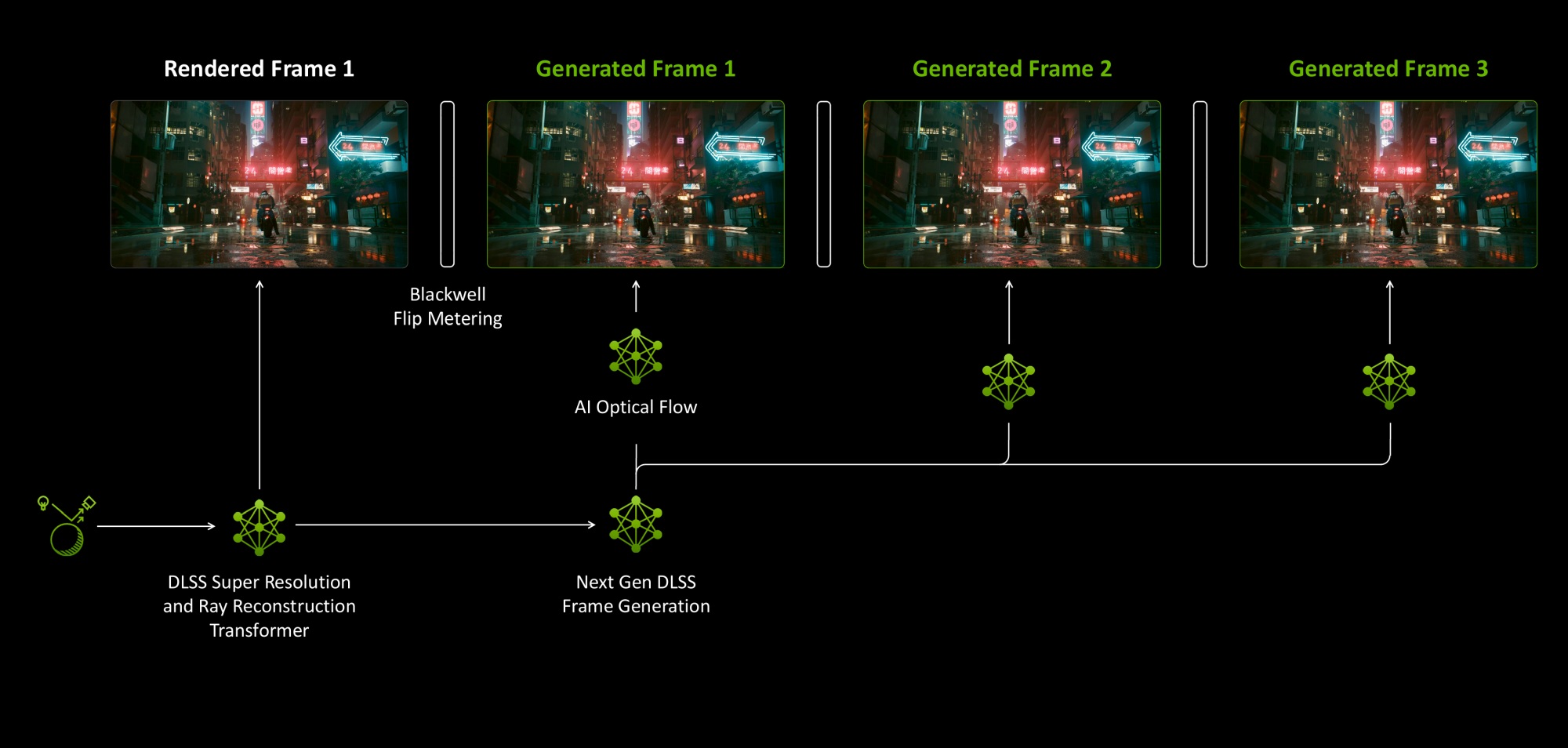
MFG использует в два раза больше данных для построения, требует более мощных тензорных блоков и процессор AIMP, поэтому технология работает только на новых видеокартах Blackwell.
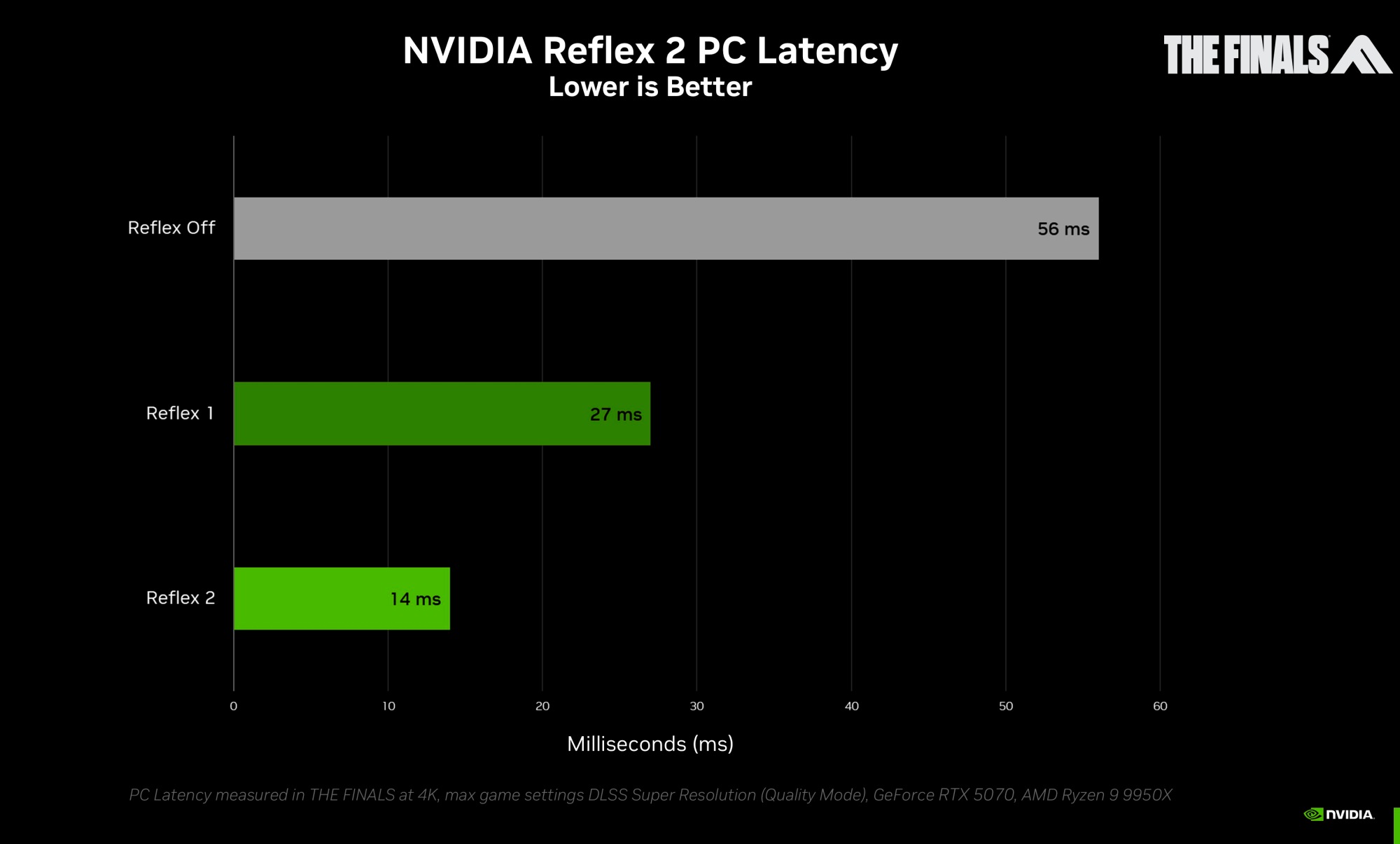
Главной проблемой генерации является низкая отзывчивость. Новые алгоритмы MFG и дополнительная технология Reflex 2 частично решают эту проблему.
Reflex 2
Технология призвана уменьшить задержки между вводом игрока и действием на экране. В первом поколении Reflex были оптимизированы разные этапы графического конвейера, а теперь NVIDIA пошла еще дальше и внедрила деформацию кадра Frame Warp. Пока GPU получает данные кадра для отрисовки, CPU уже просчитывает смещение камеры для следующего кадра на основе движений игрока. Frame Warp получает данные о смещении в последний момент перед отрисовкой кадра и ранее готовности следующего кадра. И при визуализации учитывается это небольшое смещение.
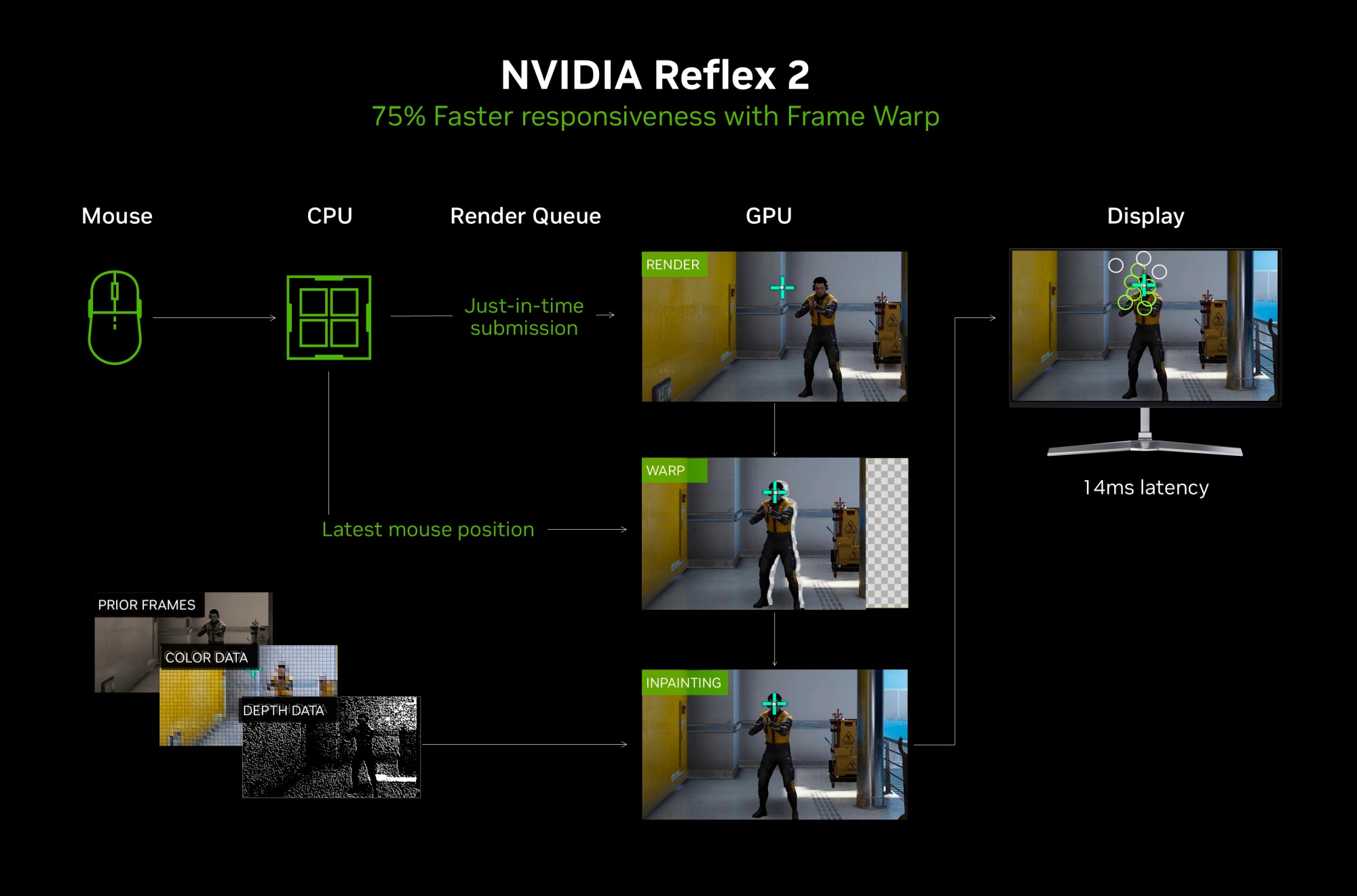
Из-за быстрого изменения данных в кадре возникают пустые пятна в зонах движения объектов. Они заполняются данными соседних кадров. Это прорывной метод для повышения отзывчивости, и он же улучшит восприятие игры при генерации кадров.
Reflex 2 пока работает только на видеокартах GeForce RTX 50, но в будущем ее сделают доступной и для более старых моделей.
Нейронные шейдеры и нейронный рендеринг
В этом поколении NVIDIA вводит новые нейронные шейдеры. И графические процессоры Blackwell создавались специально под новый тип шейдеров.
Шейдер — это программа, которая работает на GPU для управления визуализации графики. На ранних этапах развития графики использовался конвейер с фиксированными функциями. В 2000 году вместе с DirectX 8.0 и OpenGL 1.4 появились вершинные шейдеры. В DirectX 9.0 добавили пиксельные шейдеры, аппаратная поддержка которых была реализована в GeForce 3, выпущенной в 2001 году. Следующим этапом стало внедрение унифицированной шейдерной архитектуры в DirectX 10 в 2006 году. Compute Shaders и тесселяция были добавлены в DirectX 11 в 2009 году. Следующий API DirectX 12 расширил возможности геометрического конвейера за счет Primitive и Mesh Shaders, а также была добавлена трассировка лучей с ускорением структуры BVH (Bounding Volume Hierarchy) для просчета пересечения луча с геометрией сцены.
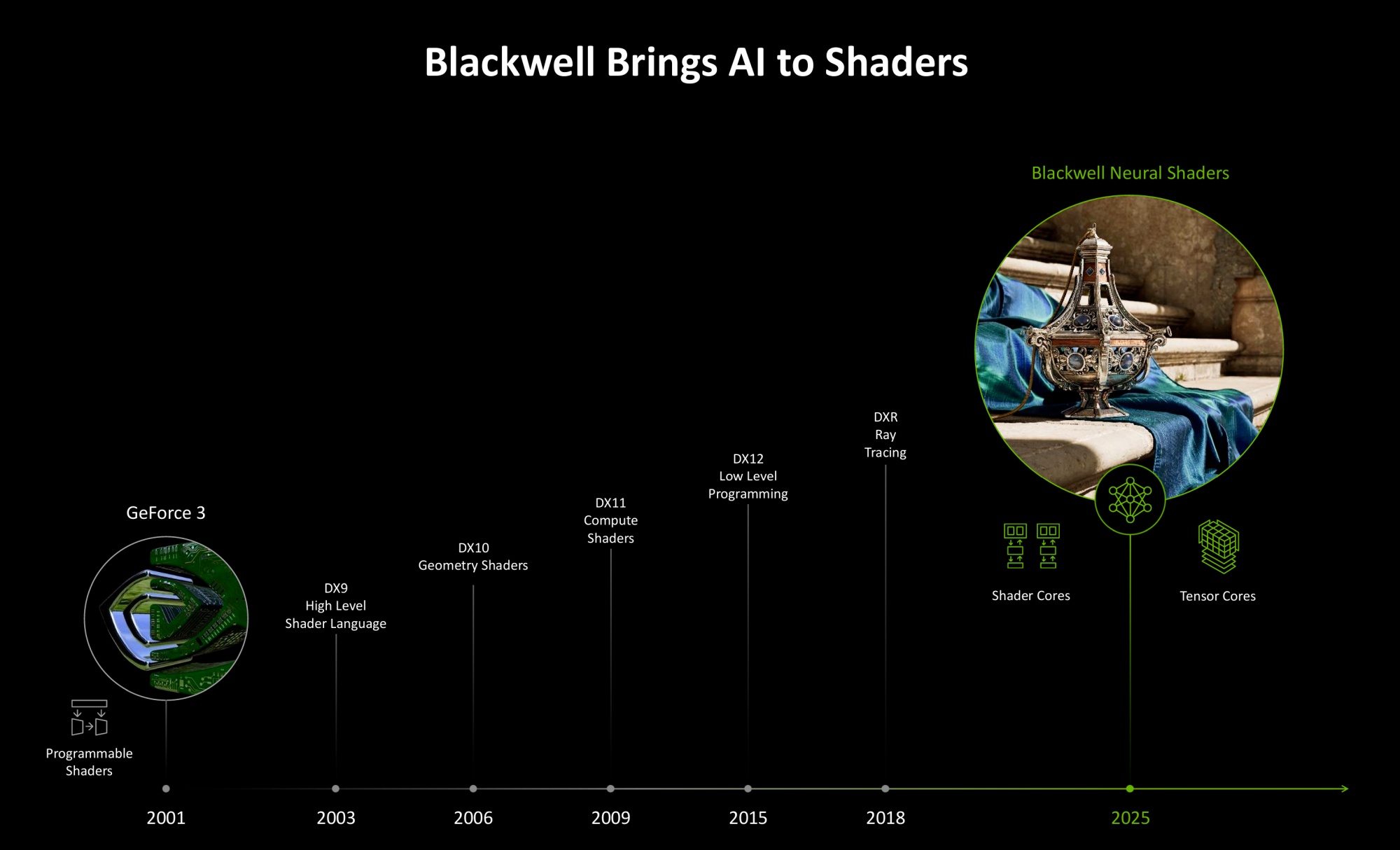
Нейронные шейдеры (Neural Shaders) станут новым этапом развития графики. Первые шейдеры уже доступны для Blackwell, и новые реализации могут внедряться в будущем. В нейронных шейдерах разработчик может использовать небольшие нейронные сети для аппроксимации результата вместо детального кода для всех функций. Neural Shaders позволяют обучать нейронные сети для эффективных приближений сложных алгоритмов, которые вычисляют, как свет взаимодействует с поверхностями, эффективно распаковывают текстуры, которые хранятся в видеопамяти в сжатом виде, предсказывают непрямое освещение на основе ограниченных данных и приблизительное подповерхностное рассеивание света. И это лишь некоторые варианты применения нейронных шейдеров, со временем их будет больше, и такой тип шейдеров когда-то может стать основным в 3D-графике.
NVIDIA уже предлагает несколько готовых к внедрению технологий на базе нейронных шейдеров.
RTX Neural Materials — для нейронной аппроксимации математических моделей сложных многослойных материалов
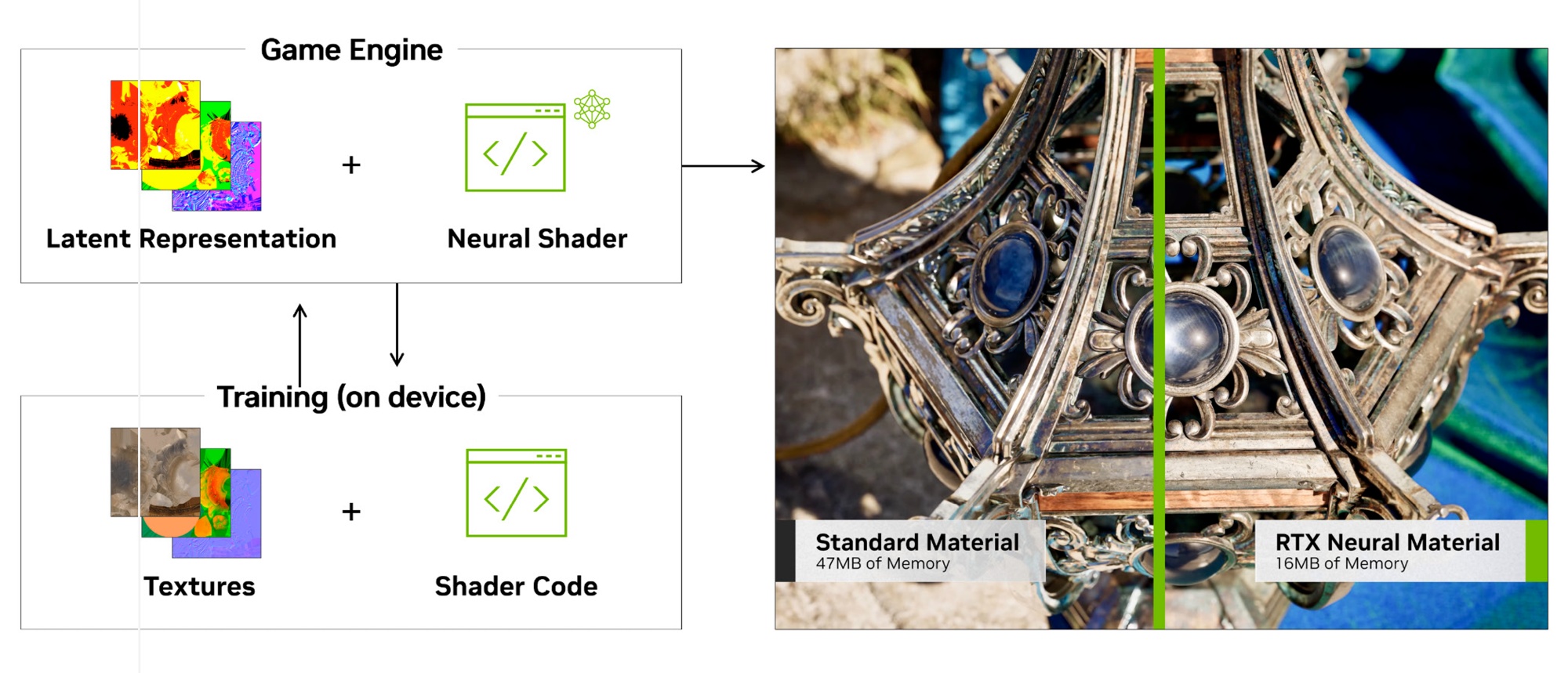
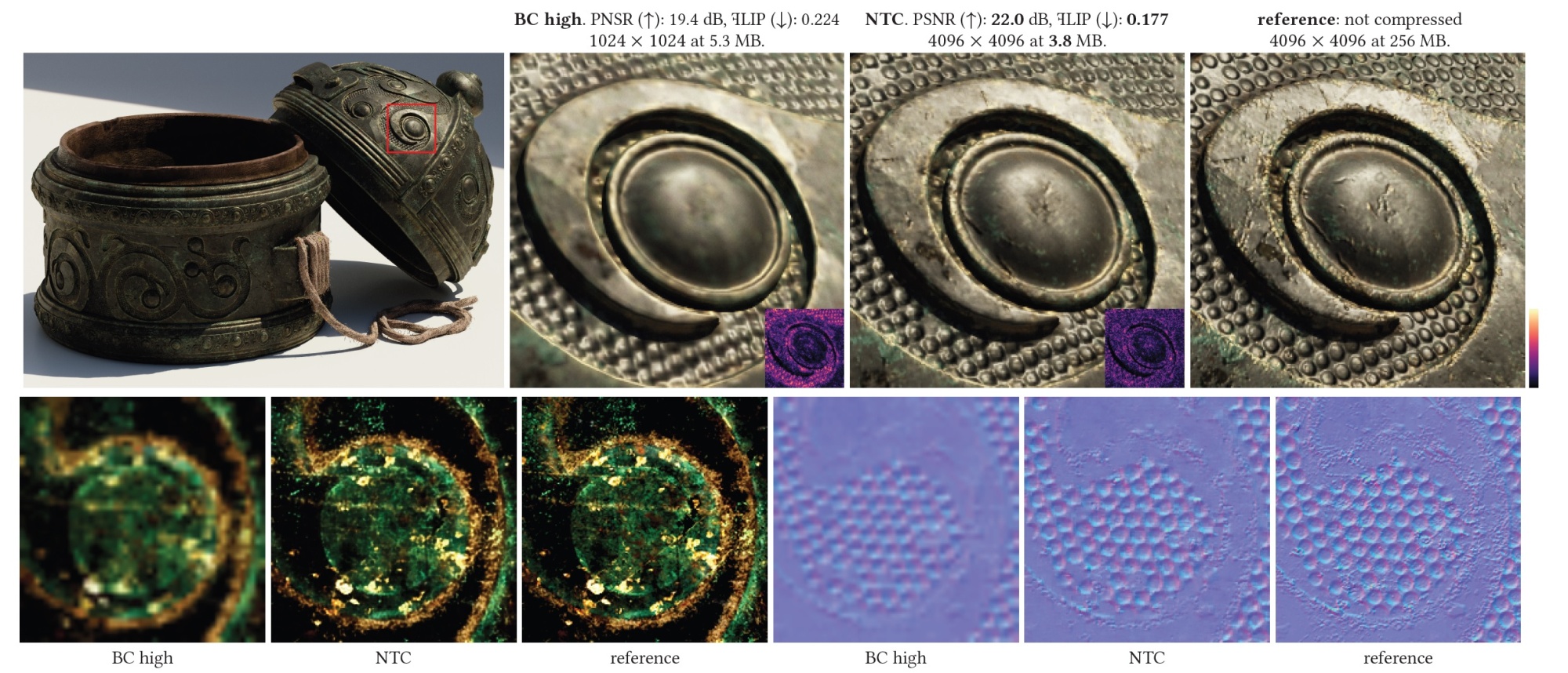
RTX Neural Texture Compression (NTC) — для более эффективного сжатия и распаковки текстур материалов, что также снижает использование видеопамяти
Neural Radiance Cache (NRC) — для оптимизации и повышения производительности трассировки с выводом данных после одного отскока луча вместо множества отскоков на основе усредненной оценки и моделирования того, как бы выглядела сцена.

RTX Skin — для оптимизации подповерхностного рассеивания с трассировкой для кожи

RTX Neural Faces — для генерации более качественных 3D-моделей лиц.
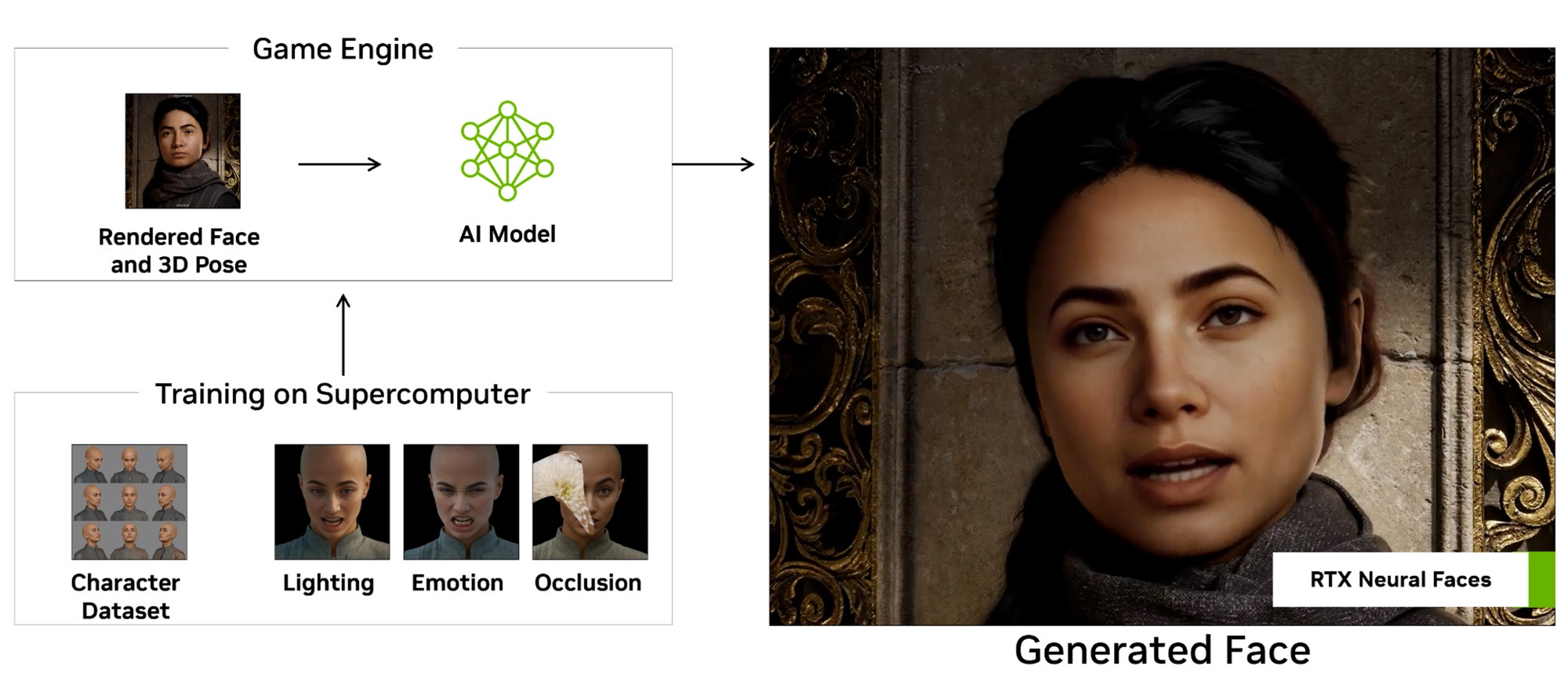
Все они являются частью набора технологий для нейронного рендеринга NVIDIA RTX Kit, куда также входят технология фильтрации RTX Texture Filtering, RTX Global Illumination и RTX Dynamic Illumination для работы с освещением, RTX Path Tracing для интеграции трассировки пути. Сюда же относится и RTX Mega Geometry.
В основном все это ориентировано на качественные режимы рендера с трассировкой, чтобы улучшить производительность именно в таких режимах.
RTX AI PC. Технологии ИИ для игр и создателей контента
Уже семь лет компания NVIDIA продвигает технологии ИИ. В 2018 году была представлена первая версия DLSS, через год появилась инициатива NVIDIA Studio, позднее технологии ИИ для трансляций, в 2023 году запустили RTX Video для улучшения потокового видео, а в прошлом году появился умный чат-бот ChatRTX.
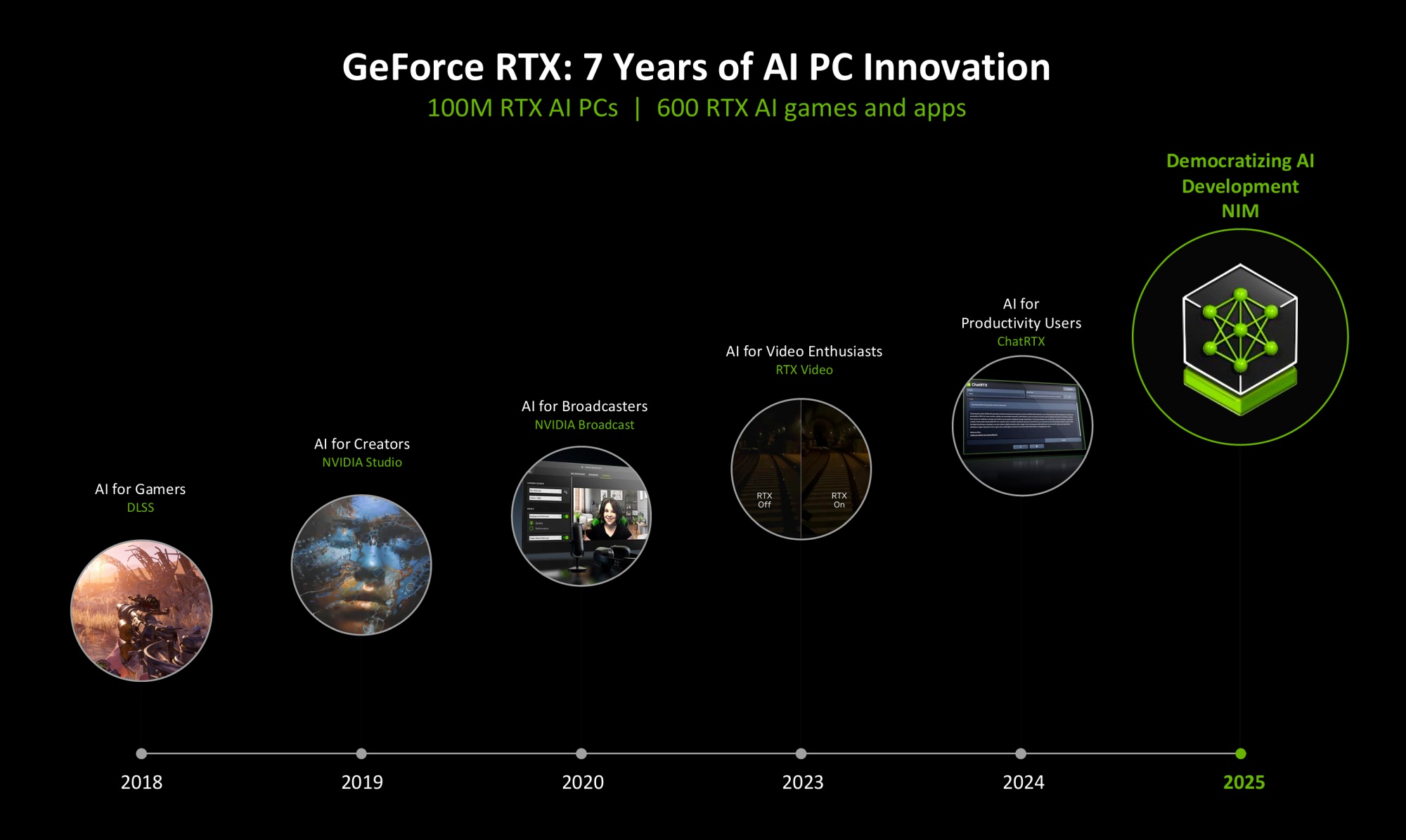
Теперь в рамках развития концепции RTX AI PC компания запускает набор микросервисов NVIDIA NIM, которые используют генеративный ИИ и разные инструменты для разработки. Сюда относятся разные ИИ-агенты для работы с программным кодом, изображениями, языковыми моделями и прочее. Они просты для внедрения, могут подключаться через облако или работать локально через стандартные API, оптимизированы для выполнения на видеокартах GeForce RTX

NVIDIA внедряет технологии ИИ не только в сферу рендера. В играх важное значение имеет мир с неигровыми персонажами. Набор технологий в рамках платформы NVIDIA ACE (Avatar Cloud Engine) призван оживать NPC, сделать их умнее и вывести общение с ними на новый уровень. Задача таких автономных персонажей взаимодействие с игроком, восприятие, способность к познанию и действиям вместе с генерацией речи и анимацией в соответствии с этими действиями.
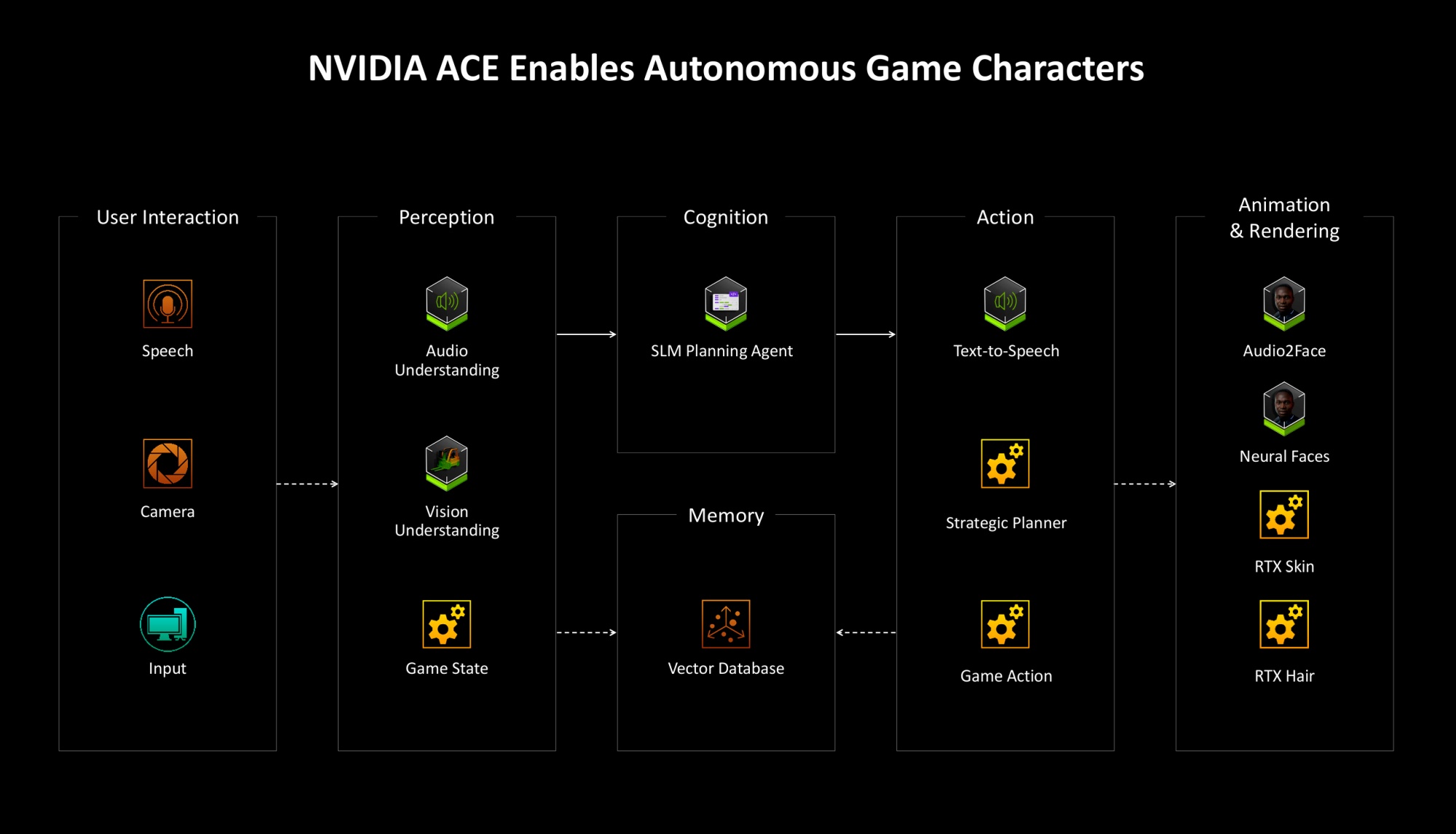
Технологии NVIDIA ACE уже внедряются игровым разработчиками. Audio2Face использовалась в Alien: Rogue Incursion и S.T.A.L.K.E.R. 2 для адаптации лицевой анимации под речь. И теперь компания предлагает уже вторую версию этой технологии. Среди новых инструментов — преобразование текста в анимацию движений тела. А RTX Neural Faces, RTX Skin и RTX Hair можно использовать для реалистичной генерации лиц персонажей.
На базе NVIDIA ACE будут реализованы умные напарники в PUBG: Battlegrounds. Разработчики даже ввели новый термин CPC (Co-Playable Character) — этот персонаж действует с вами в команде, помогает и реагирует на ваши команды.
Аналогичных напарников в будущем добавят в Naraka: Bladepoint. Умные NPC появятся в симуляторе жизни inZOI — они будут планировать свой распорядок дня, принимать решения и реагировать на события, каждый будет обладать своим характером, памятью и будет выстраивать свои отношения с другими NPC.
Видеокарты Blackwell расширяют возможности для создателей контента. Архитектура, ориентированная на вычисления ИИ, обеспечит серьезное преимущество в различных генеративных сервисах. Например, генерация изображения в модели Flux с применением нового формата FP4 в три раза быстрее на RTX 5090, чем на RTX 4090. А набор сервисов NIM упростит работы с изображениями и графикой.

Мы уже упоминали поддержку формата кодирования цвета 4:2:2, что позволяет работать с контентом с полупрофессиональных и профессиональных камер. А усиленный кодировщик обеспечит быструю обработку и кодирование видео высокого разрешения.
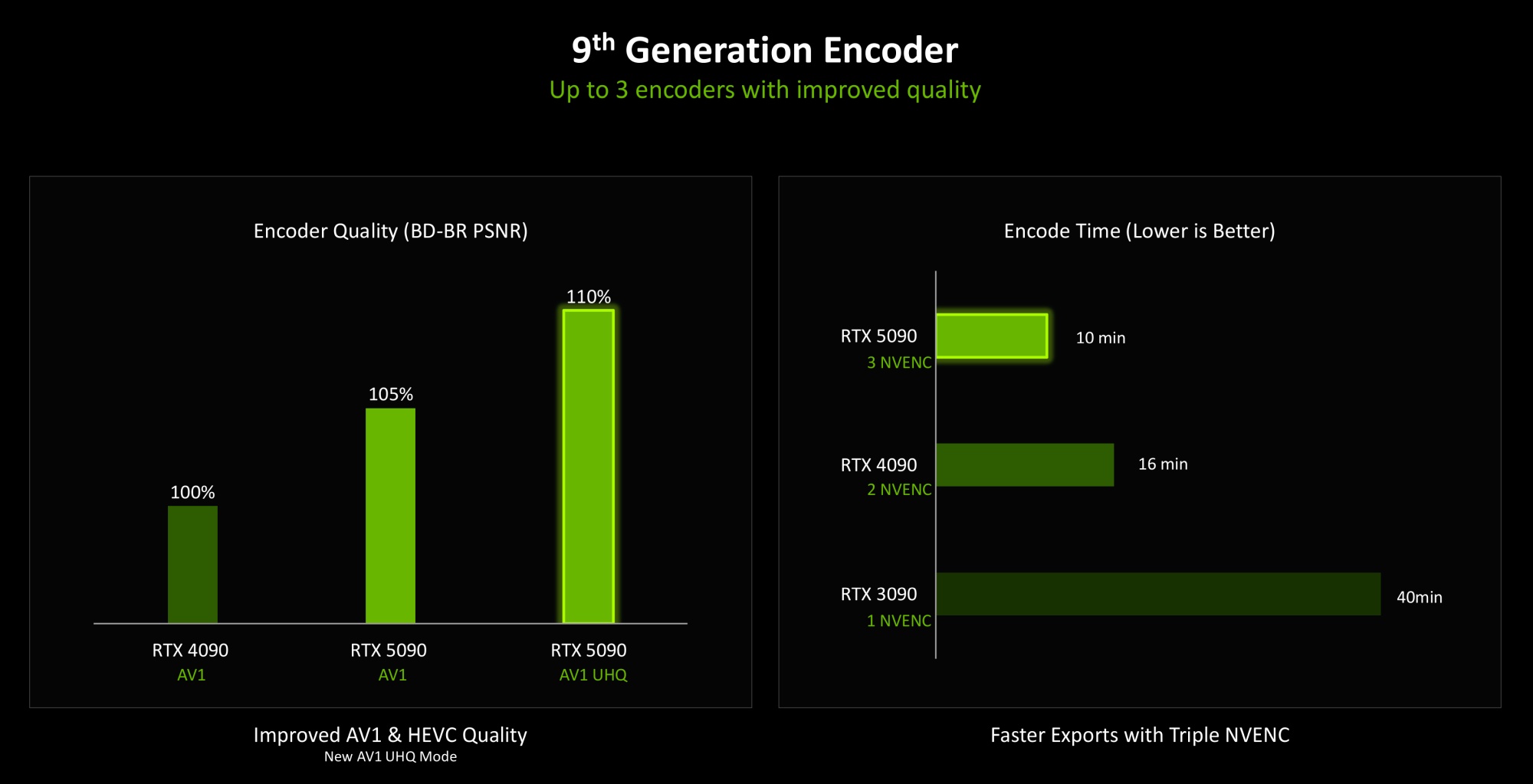
В сочетании с многопоточным аппаратным ускорением вы получаете лучшее решение для видеомонтажа и работы с несколькими видеопотоками.
Для стримеров компания NVIDIA предлагает приложение Streamlabs Intelligent Streaming Assistant для простой технической настройки параметров стрима и элементов интерфейса. Знакомое приложение для трансляций NVIDIA Broadcast получит новые функции для улучшения качества звука, удаления и создания фона, коррекции освещения.

C NVIDIA Broadcast вы получите качество звука и картинки лучше, чем изначально обеспечивает ваш микрофон и камера.

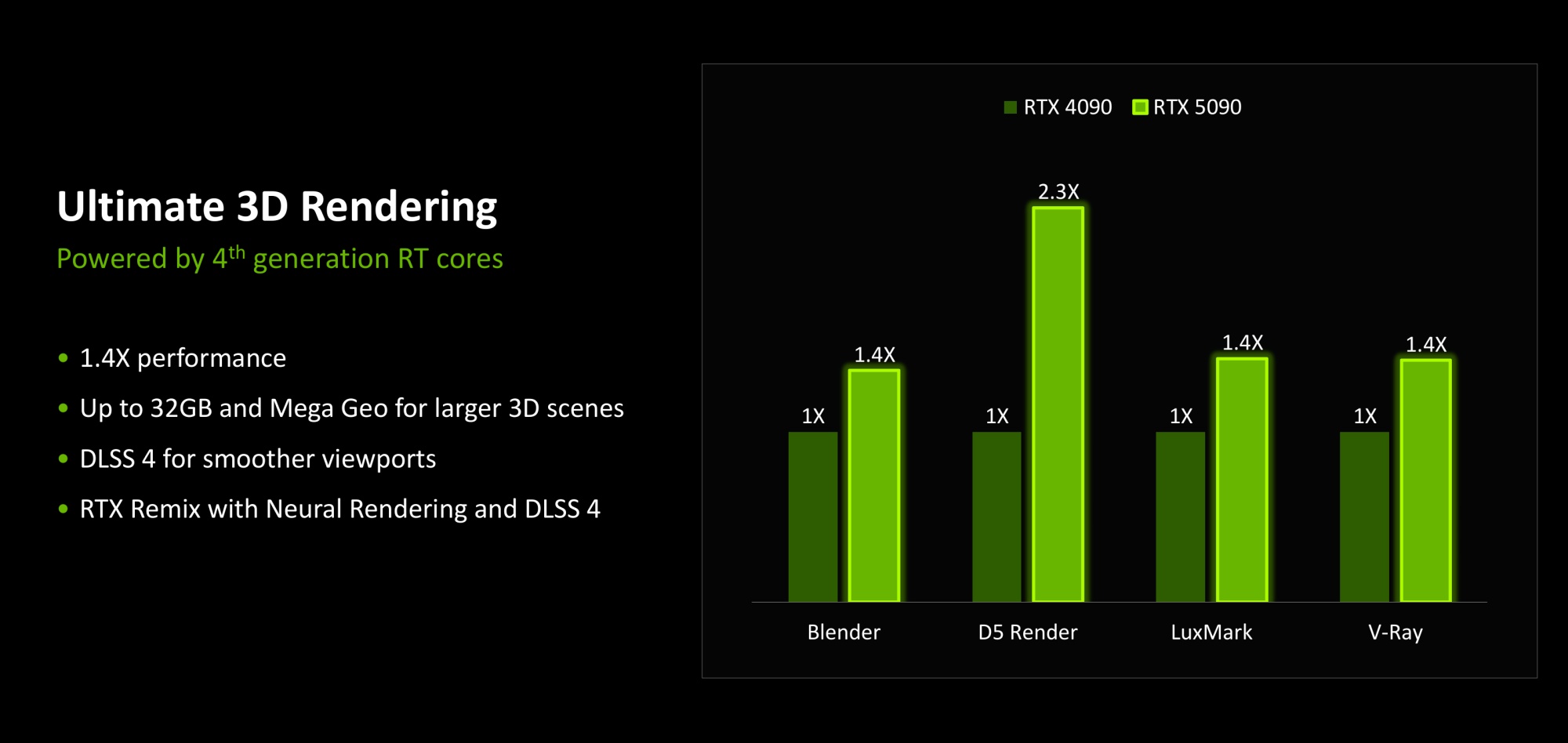
GeForce RTX 5090 является ультимативным решением для 3D-рендера. Прирост производительности в программах рендера от 40% и выше (относительно GeForce RTX 4090), плюс высокий объем памяти и поддержка новых технологий.
Конструкция GeForce RTX 50 Founders Edition
Возросшее тепловыделение видеокарт старшего сегмента потребовало нового подхода для качественного охлаждения. Референсные видеокарты прошли эволюцию от турбинной конструкции к варианту с двумя осевыми вентиляторами. В серии GeForce RTX 30 вентиляторы уже были размещены с двух сторон для лучшей продуваемости. В новой серии нам предлагают конструкцию с двумя большими осевыми вентиляторами и со сквозными отверстиями с обратной стороны.
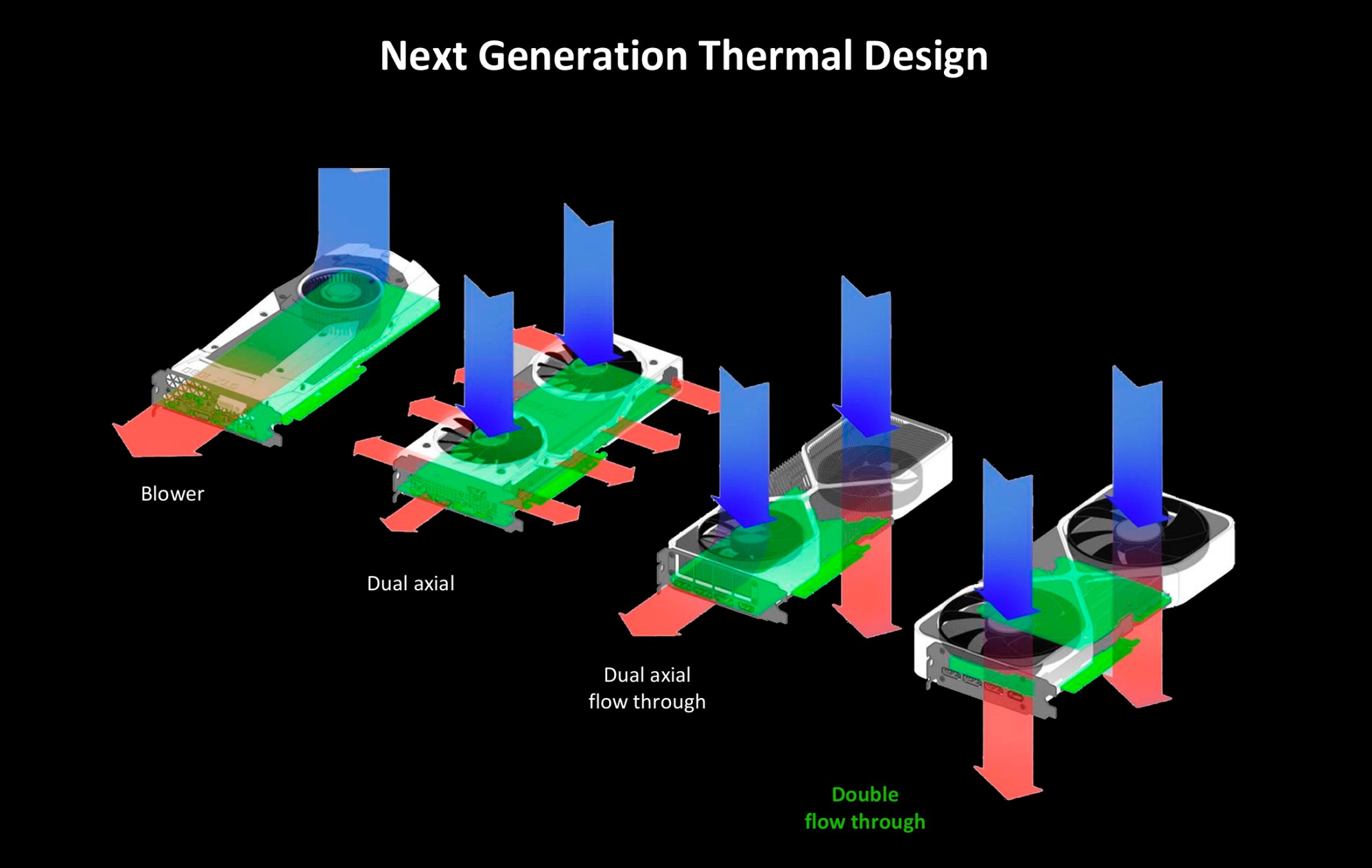
Длина эталонной версии GeForce RTX 5090 лишь 30 см при ширине 14 см и толщине 4 см, масса 1,8 кг. И это весьма удивительно для продукта с мощностью в 575 Вт. Причем это самая компактная версия GeForce RTX 5090, которая единственная подходит для малогабаритных корпусов SFF.


Фотографии GeForce RTX 5090 Founders Edition от TechPowerUp
Конструкция новых видеокарт в исполнении NVIDIA предусматривает наличие в центре компактной платы с плотным монтажом элементом. Со стороны чипа и микросхем памяти устанавливается радиатор с большой испарительной камерой и толстыми тепловыми трубками. В качестве термоинтерфейса используется жидкий металл. Трубки несут не себе два больших радиаторных блока, которые из-за отсутствия платы свободно продуваются крупными вентиляторами. Все пространство внутри кожуха занимает радиатор, и дополнительный радиатор накрывает обратную сторону платы.

Такая система охлаждения со сквозным продувом оказывается весьма эффективной внутри современного корпуса с правильно организованным воздушными потоками.


Фотографии GeForce RTX 5090 Founders Edition от TechPowerUp
Новый флагман GeForce RTX 5090 компактнее предшественника GeForce RTX 4090 и меньше всех вариантов в исполнении партнеров. Топовые версии от ASUS и других производителей имеют толщину до четырех слотов и оснащены четырьмя вентиляторами.

GeForce RTX 5090 Founders Edition в сравнении с GeForce RTX 4090 Founders Edition
Конструкция эталонной GeForce RTX 5090 является определенным чудом инженерной мысли. Это касается как охлаждения, так и чрезвычайно сложной компактной PCB.


Печатная плата GeForce RTX 5090
Следующая в иерархии видеокарта GeForce RTX 5080 Founders Edition имеет длину 30 см при ширине 13,5 см и толщине 4 см. Во многом она повторяет конструкцию флагмана, но с оснащена малой испарительной камерой в основании. Также используется классическая термопаста вместо жидкого металла. Проще радиатор с обратной стороны платы.

Фотография GeForce RTX 5080 Founders Edition от TechPowerUp
Характеристики видеокарт RTX 50-й серии
На данный момент известны характеристики четырех видеокарт Blackwell. Все они приведены в таблице. Для наглядности также приведены характеристики аналогичных моделей прошлого поколения, без учета более поздних модификаций линейки Super
|
GeForce RTX 5090 |
GeForce RTX 5080 |
GeForce RTX 5070 Ti |
GeForce RTX 5070 |
GeForce RTX 4090 |
GeForce RTX 4080 |
GeForce RTX 4070 Ti |
GeForce RTX 4070 |
|
|
Архитектура |
Blackwell |
Blackwell |
Blackwell |
Blackwell |
Ada Lovelace |
Ada Lovelace |
Ada Lovelace |
Ada Lovelace |
|
Ядро |
GB202 |
GB203 |
GB203 |
GB205 |
AD102 |
AD103 |
AD104 |
AD104 |
|
Техпроцесс, нм |
TSMC 4N |
TSMC 4N |
TSMC |
TSMC 4N |
TSMC 4N |
TSMC 4N |
TSMC 4N |
TSMC 4N |
|
Количество транзисторов, млн. шт |
92200 |
45600 |
45600 |
31000 |
76300 |
45900 |
35800 |
35800 |
|
Площадь ядра, мм² |
750 |
378 |
378 |
263 |
609 |
379 |
294 |
294 |
|
SM |
170 |
84 |
70 |
48 |
128 |
76 |
46 |
46 |
|
CUDA-ядра |
21760 |
10752 |
8960 |
6144 |
16384 |
9728 |
7680 |
5888 |
|
Тензорные ядра |
680 |
336 |
280 |
192 |
512 |
304 |
240 |
184 |
|
Ядра RT |
170 |
84 |
70 |
48 |
128 |
76 |
60 |
46 |
|
Текстурные блоки TMU |
680 |
336 |
280 |
192 |
512 |
304 |
240 |
184 |
|
Блоки растеризации ROP |
176 |
112 |
96 |
64 |
176 |
112 |
80 |
64 |
|
FP32 FLOPS |
104,8 |
56,3 |
43,9 |
30,9 |
82,6 |
48,8 |
40,1 |
29,15 |
|
Tensor TOPS FP16 |
838 (3352 FP4) |
450 (18012 FP4) |
351,5 (1406 FP4) |
246,9 (987 FP4) |
661 (1321 FP8) |
390 (780 FP8) |
320,5 (641 FP8) |
233 (466 FP8) |
|
RT FLOPS |
317,5 |
170,6 |
133,2 |
96,6 |
191 |
113 |
93 |
67 |
|
L2 кэш, МБ |
96 |
64 |
48 |
40 |
72 |
64 |
48 |
36 |
|
Частота ядра (Base Clock), МГц |
2017 |
2285 |
2300 |
2165 |
2235 |
2205 |
2310 |
1920 |
|
Частота ядра (Boost Clock), МГц |
2407 |
2617 |
2452 |
2512 |
2520 |
2505 |
2610 |
2475 |
|
Шина памяти, бит |
512 |
256 |
256 |
192 |
512 |
256 |
192 |
192 |
|
Тип памяти |
GDDR7 |
GDDR7 |
GDDR7 |
GDDR7 |
GDDR6X |
GDDR6X |
GDDR6X |
GDDR6X |
|
Частота памяти Гбит/с |
28000 Гбит/с |
30000 |
28000 |
28000 |
21000 |
22400 |
21000 |
21000 |
|
Объём памяти, ГБ |
32 |
16 |
16 |
12 |
24 |
16 |
12 |
12 |
|
ПСП памяти, ГБ/с |
1792 |
960 |
896 |
672 |
1008 |
716,8 |
504,2 |
504,2 |
|
Интерфейс |
PCI-E 5.0 |
PCI-E 5.0 |
PCI-E 5.0 |
PCI-E 5.0 |
PCI-E 4.0 |
PCI-E 4.0 |
PCI-E 4.0 |
PCI-E 4.0 |
|
Мощность TGP, Вт |
575 |
360 |
300 |
250 |
450 |
320 |
285 |
200 |
На видеокарты установлены такие рекомендуемые цены:
- GeForce RTX 5090 $1999
- GeForce RTX 5080 $999
- GeForce RTX 5070 Ti $749
- GeForce RTX 5070 $649
В реальности из-за дефицита все они пока продаются намного дороже заявленной стоимости. А если говорить о нереференсных моделях с высоким заводским разгоном и мощным охлаждением, то тут наценки просто огромны. Цена на топовые GeForce RTX 5090 стремится к 3 тысячам долларов, а некоторые GeForce RTX 5080 продают по две тысячи.
Производительность GeForce RTX 5090 и GeForce RTX 5080
Для иллюстрации производительности воспользуемся слайдами от NVIDIA для GeForce RTX 5090, GeForce RTX 5080 и GeForce RTX 5070 Ti.
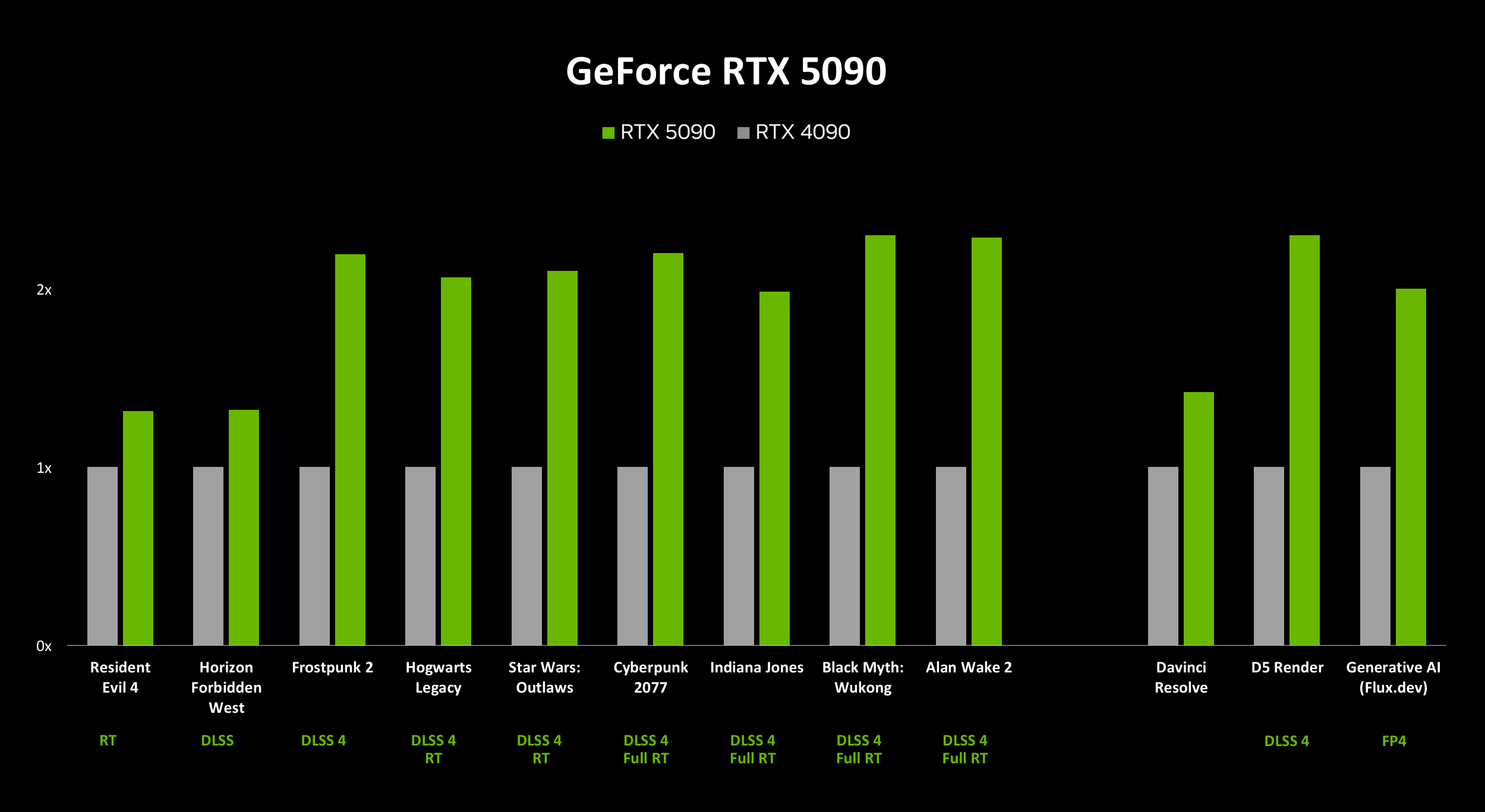

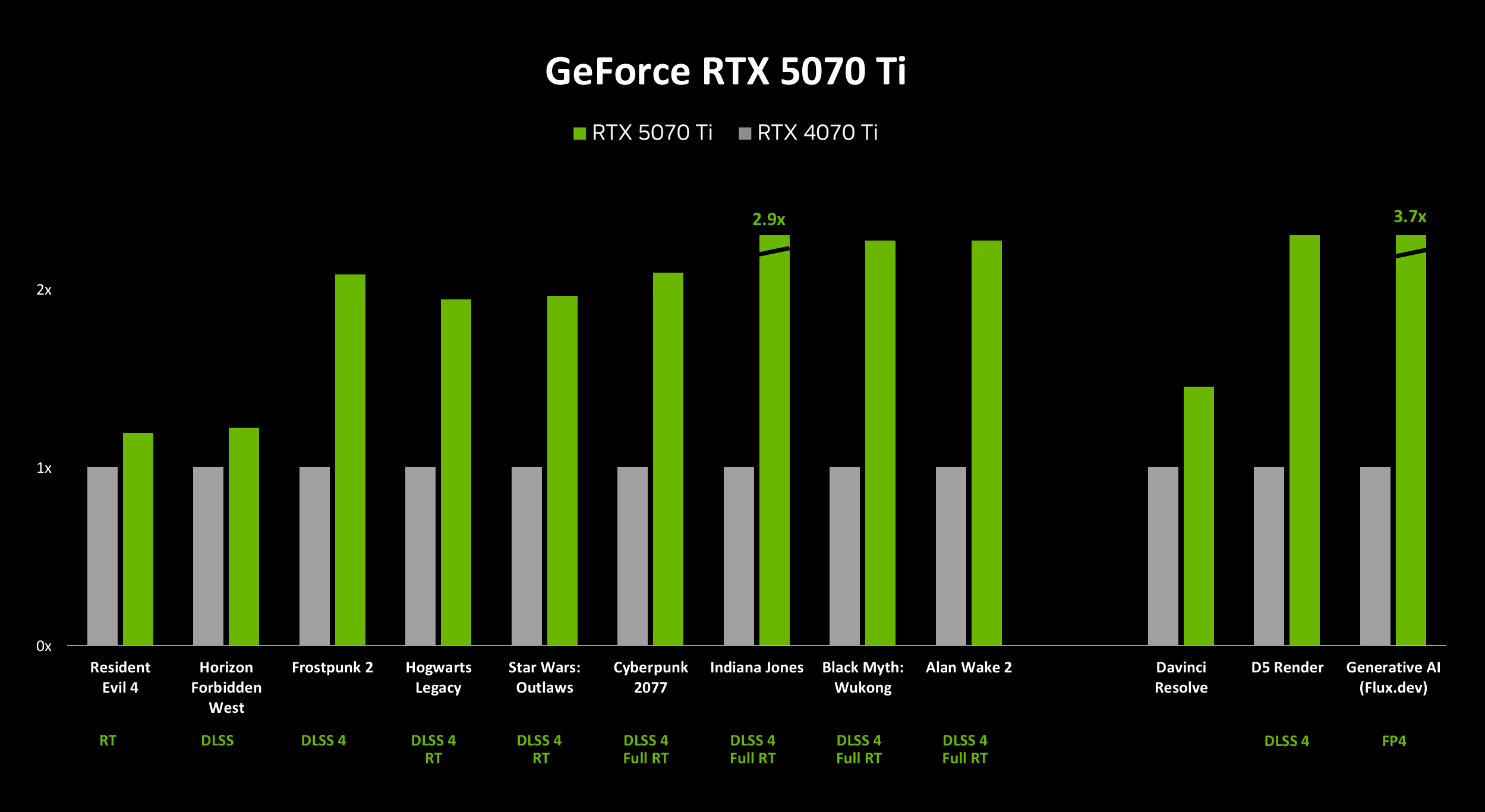
Как видим, даже сама NVIDIA признает, что преимущество новых моделей относительно старых видеокарт сильно зависит от конкретной игры и приложения. С генерацией кадров DLSS 4 MFG и трассировкой лучей можно рассчитывать и на двукратный рост частоты кадров. Но в Resident Evil 4 и Horizon Forbidden West разница между видеокартами нового и старого поколения очень небольшая.
Далее несколько графиков с результатами независимых тестов GeForce RTX 5090/5080/5070 Ti от TechPowerUp. Поскольку это решения топового сегмента, то основной интерес вызывает их потенциал в 4K при максимальных настройках графики.
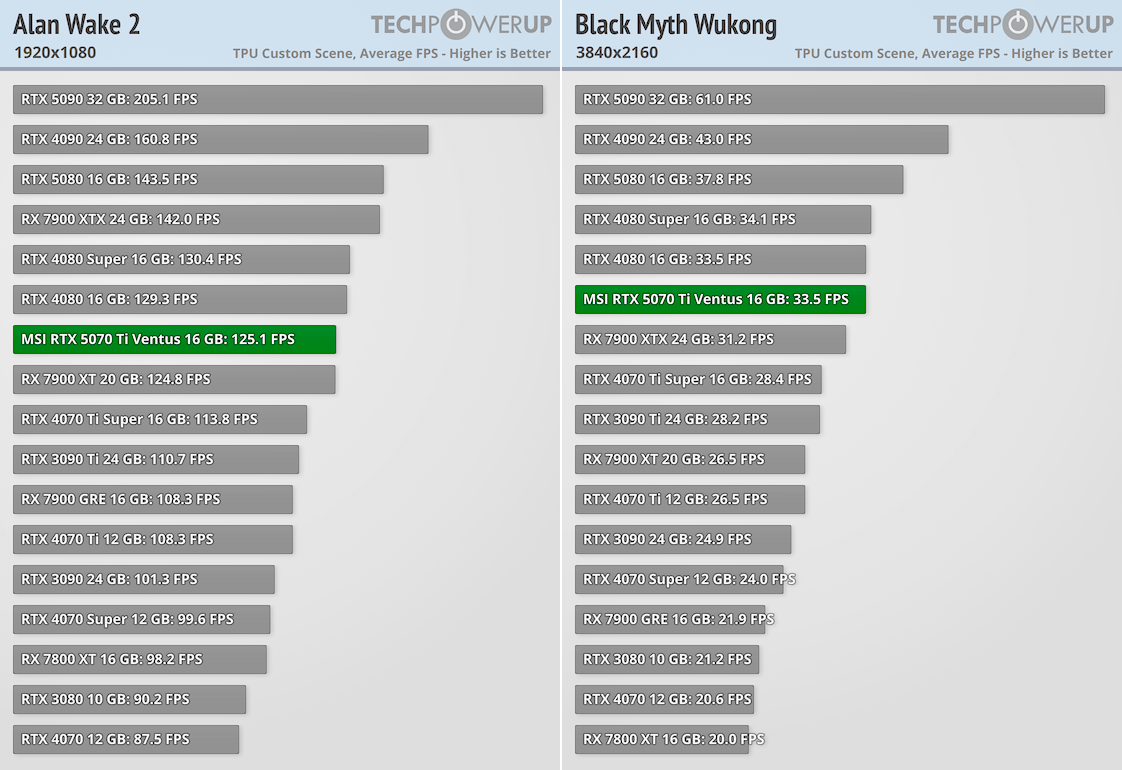
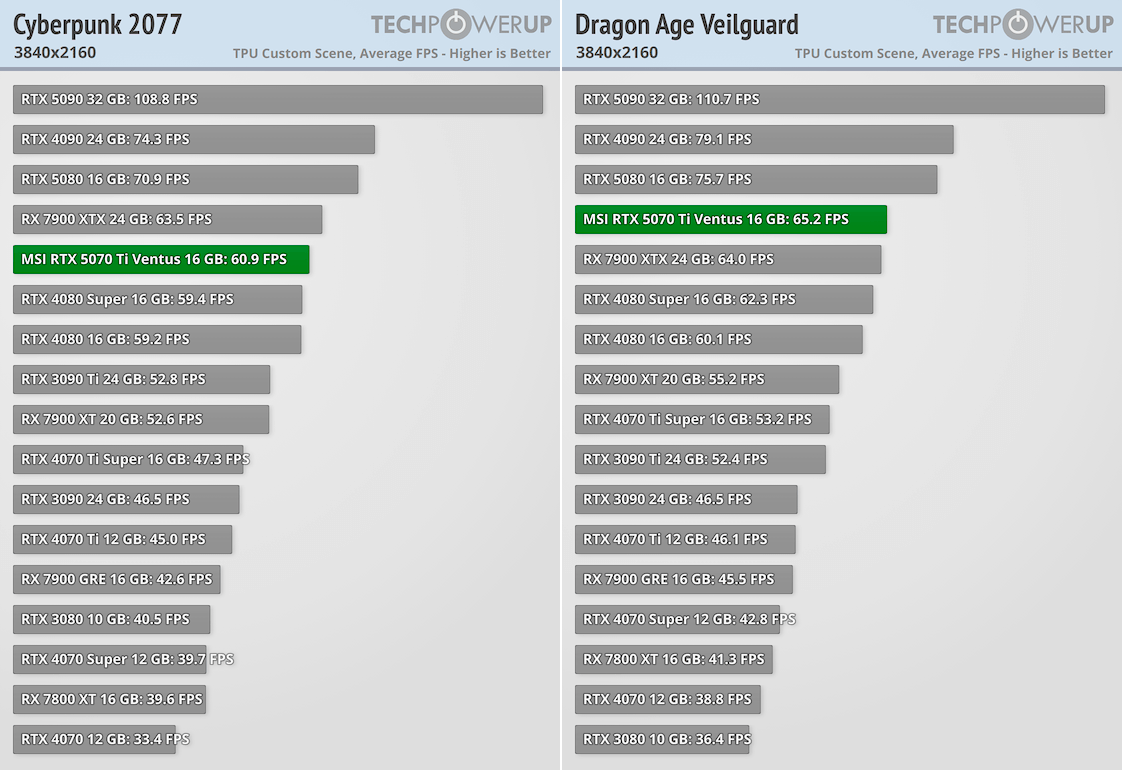
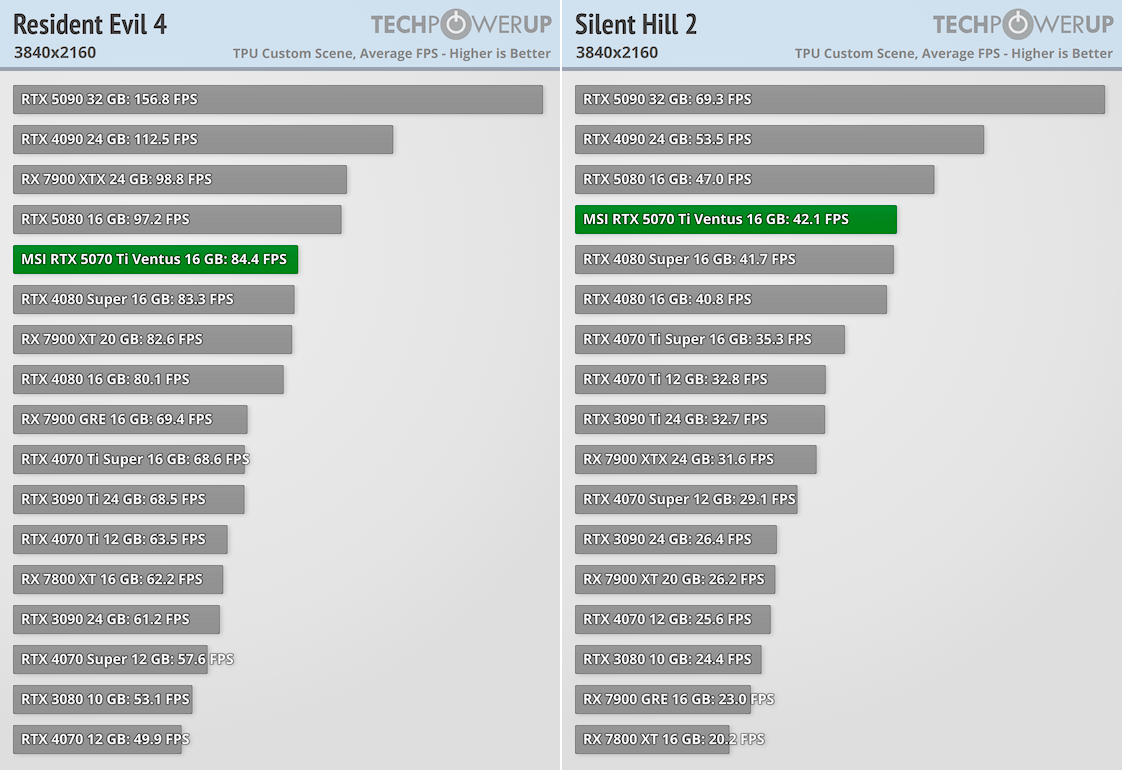
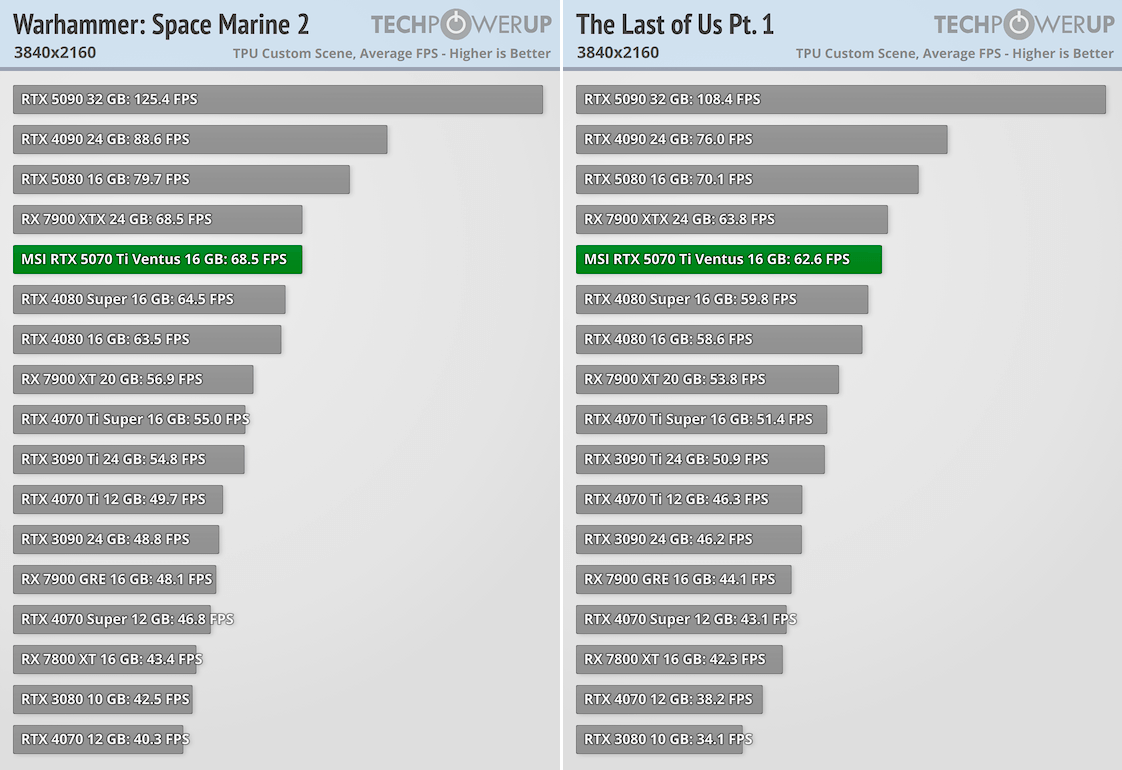
GeForce RTX 5090 быстрее GeForce RTX 4090 на 30-42%, а в Cyberpunk 2077 разница более 46%. GeForce RTX 5080 производительнее GeForce RTX 4080 на 10-20%, максимальный отрыв в 26% наблюдается в Dragon Age: Veilguard. Но у NVIDIA есть еще GeForce RTX 4080 Super, разница с которой меньше. GeForce RTX 5070 Ti показывает результаты на уровне GeForce RTX 4080, кое-где даже обгоняя эту видеокарту (наибольший отрыв в 8% наблюдается в Veilguard). Тут правда речь идет о модели Ventus с заводским разгоном, но он совсем небольшой.
Технология DLSS и многокадровая генерация способны кардинально повысить fps. В требовательных играх DLSS Quality дает ускорение до 80%, а вместе с генерацией 3-х кадров это ускорение в 4 раза и выше. В производительном режиме DLSS Performance с генерацией 3-х кадров можно получить пятикратный рост быстродействия относительно нативного режима.
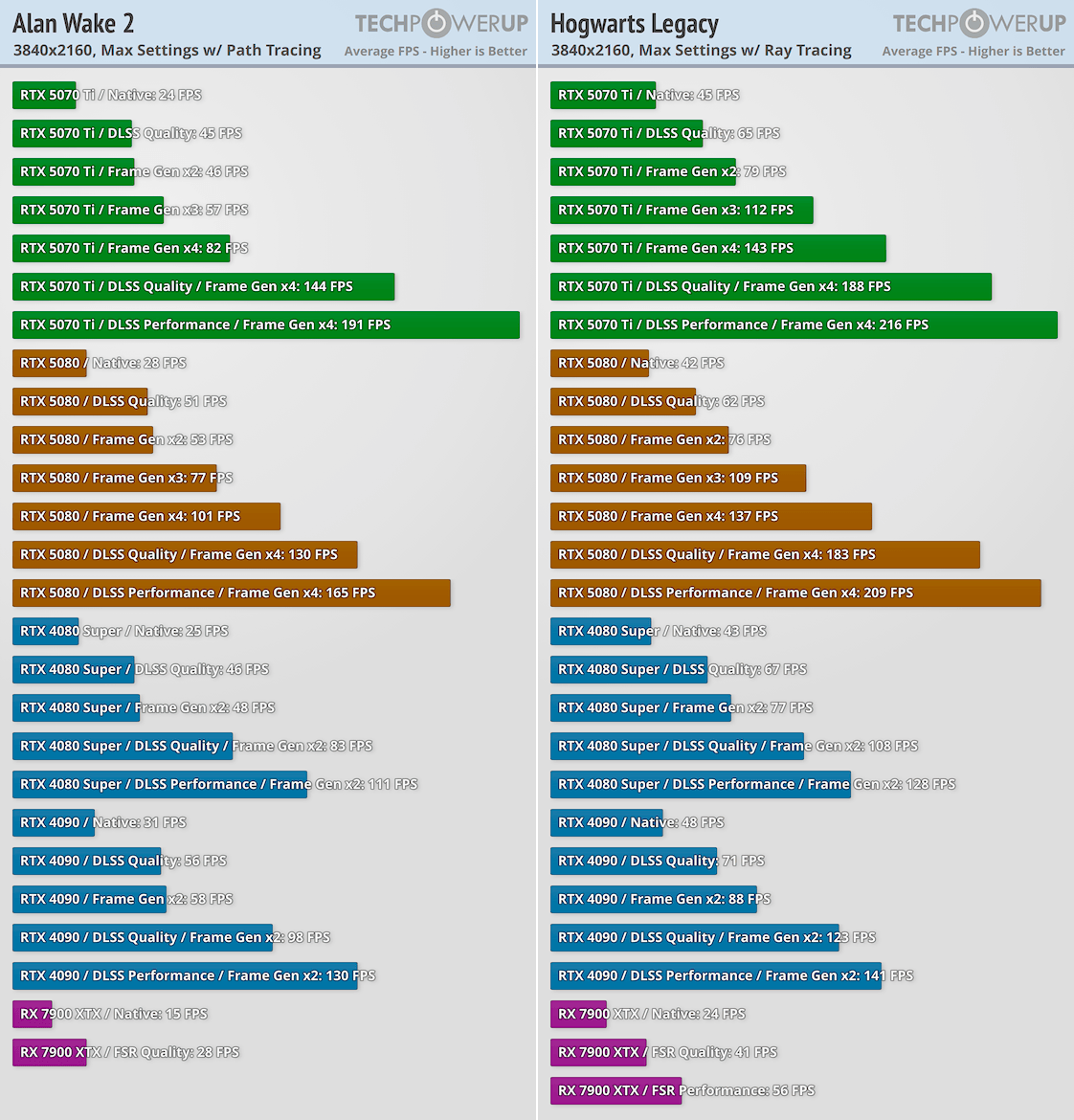
При максимальной генерации кадров GeForce RTX 5080 способна обогнать GeForce RTX 4090 со старой генерацией. А GeForce RTX 5090 показывает двукратное и более высокое преимущество относительно GeForce RTX 4090.
Выводы
Новая серия видеокарт GeForce RTX 50 выходит в условиях, когда освоение новых технологических процессов проходит очень медленно и стоимость производства постоянно растет. Улучшать производительность графических чипов за счет увеличения количества транзисторов становится все сложнее. Нужны новые подходы, и NVIDIA их ищет. Компания делает ставку на внедрение глубокого обучения и нейросетей непосредственно в графический конвейер. Новая архитектура Blackwell привносит много оптимизаций для новых нейронных шейдеров, которые призваны обеспечит лучшее качество графических эффектов при более оптимальном использовании ресурсов GPU. И это может стать толчком к новому этапу развития 3D-графики, как когда-то было с появлением аппаратного ускорения трассировки лучей в GeForce RTX 20-й серии. Можно говорить об определенном потенциале на будущее, который мы пока в полной мере не можем ощутить. При этом ряд новых нейронных технологий должен уменьшить использование видеопамяти, что в какой-то мере должно компенсировать наличие 12 и 8 гигабайт видеобуфера в бюджетных видеокартах Blackwell.
Но уже сейчас можно оценить улучшения в технологии DLSS и новую многокадровую генерацию. Качество изображения с масштабированием на базе Transformer однозначно лучше, и улучшения DLSS Super Resolution могут почувствовать пользователи всех видеокарт GeForce RTX. А вот многокадровая генерация, которая создает до трех кадров, является эксклюзивным решением для GeForce RTX 50. В плане отзывчивости технология не заменит полноценный рендер кадров, но компании удалось добиться серьезного снижения задержек, и новая генерация воспринимается весьма хорошо и плавно. Это серьезное преимущество в производительности для совместимых игр и главный аргумент в пользу новых видеокарт. Также видеокарты на архитектуре Blackwell получили значительный апгрейд ядер для ускорения трассировки. И в технологичных играх с трассировкой пути тоже можно рассчитывать на неплохое ускорение относительно прошлого поколения.
В обычных растровых играх ускорение может не столь впечатляющее, ведь для стандартного рендера улучшений мало. В некоторых случаях можно наблюдать разницу в несколько процентов между новыми и старыми видеокартами одного класса, что вполне укладывается в рамки небольшого увеличения количества CUDA-ядер и рабочих частот. И переход с GeForce RTX 4090/4080/4070 на новые видеокарты аналогичного класса может показаться сомнительным решением. Но если в вашем ПК трудится более старая видеокарта, то вы ощутите качественный и серьезный рост производительности. В условиях дефицита на старте мы бы рекомендовали пока не торопиться с покупкой и подождать стабилизации цен на GeForce RTX 50.
Нет явного прогресса в энергоэффективности, хотя NVIDIA серьезно улучшила многие механизмы для управления частотами и энергосберегающими режимами. Но в десктопном сегменте многие чипы работают на пределе возможностей. И даже тут можно констатировать, что GeForce RTX 5070 Ti потребляет чуть меньше GeForce RTX 4080 при аналогичном уровне производительности. В мобильном сегменте новые механизмы энергосбережения в режимах слабой нагрузки должны лучше проявить себя и продлить время автономной работы от аккумулятора.