На конференции по графическим технологиям в Китае компания NVIDIA представила новейшие решения для платформы глубокого обучения на базе архитектуры Pascal – графические ускорители Tesla P4, Tesla P40 и программное обеспечение, которое значительно ускоряет и оптимизирует анализ информации для сервисов, использующих искусственный интеллект (ИИ). В основе Tesla P4 процессор GP104, ранее ставший основой для GeForce GTX 1080, в основе Tesla P40 процессор GP102, использующийся также в графической карте GeForce GeForce GTX Titan X Pascal.

Tesla P40
Современные сервисы ИИ, такие, как активируемая голосом помощь, почтовые фильтры спама и движки генерации рекомендуемых фильмов и продуктов, становятся все сложнее. Нейронным сетям, которые для них нужны, требуется в 10 раз больше вычислений по сравнению с нейронными сетями еще год назад. Современные центральные процессоры не способны оперативно реагировать на запросы сервисов ИИ, что не лучшим образом сказывается на возможностях пользователей.
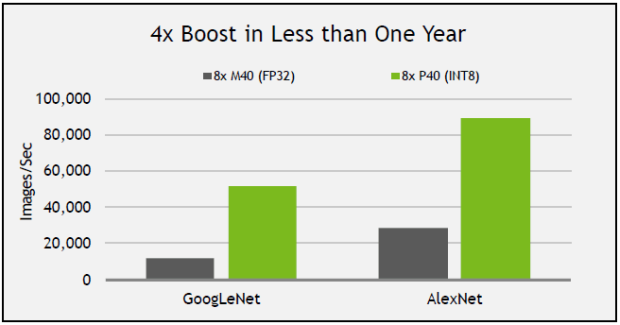
Ускорители Tesla P4 и P40 специально созданы для ускорения операций инференса – применения обученных глубоких нейронных сетей для распознавания речи, изображений и текста в ответ на запрос пользователей или устройств. Основанные на архитектуре Pascal, новые графические процессоры использую специальные инструкции инференса на базе 8-битных (INT8) данных, обеспечивая ответную реакцию в 45 раз быстрее по сравнению с CPU и в 4 раза быстрее по сравнению с GPU, представленными меньше года назад.
Ускорители Tesla P4 отличаются высочайшей экономичностью и предназначены для гипермасштабируемых дата-центров. Благодаря малым размерам и низкому энергопотреблению (от 50Вт), они подходят для любых серверов, что делает их в 40 раз экономичнее центральных процессоров в задачах использования результатов обучения нейронных сетей при обработке данных. Сервер с одним Tesla P4 может заменить 13 серверов на базе CPU, что сокращает общую стоимость владения в 8 раз, включая затраты на сервер и электричество.

Tesla P4
Tesla P40 обеспечивает максимальную пропускную способность для задач глубокого обучения. С производительностью в 47 тера-операций в секунду (TOPS) с инструкциями INT8 сервер с восемью ускорителями Tesla P40 может заменить 140 серверов на базе CPU. С учетом средней стоимости одного сервера с CPU порядка $5000, общая экономия составит более $650 000.
Спецификации
|
|
Tesla P4 |
Tesla P40 |
|
FLOPS одинарной точности* |
5,5 |
12 |
|
INT8 TOPS* (тера-операций в секунду) |
22 |
47 |
|
Ядра CUDA |
2560 |
3840 |
|
Частота GPU (Base/Boost) |
810/1063 МГц |
1303/1531 МГц |
|
Память GDDR5 |
8 ГБ |
24 ГБ |
|
Полоса пропускания памяти |
192 ГБ/с |
384 ГБ/с |
|
Энергопотребление |
50 Вт и выше |
250 Вт |
* С активированной частотой Boost
Решения Tesla P4 и P40 дополняют два новых программных продукта, предназначенных для ускорения работы ИИ-сервисов: NVIDIA TensorRT и NVIDIA DeepStream SDK.
TensorRT – это библиотека, созданная для оптимизации моделей глубокого обучения, которая обеспечивает мгновенную ответную реакцию для самых сложных сетей. Она увеличивает пропускную способность и эффективность приложений глубокого обучения путем оптимизации обученных нейронных сетей – обычно в форме 32-битных или 16-битных операций – для операций INT8 пониженной точности.
NVIDIA DeepStream SDK использует мощь сервера на базе решений на архитектуре Pascal для одновременного декодирования и анализа до 93 видеопотоков в разрешении HD в реальном времени, в отличие от семи потоков в случае с серверами на базе двух CPU. Это позволяет решить одну из сложнейших задач в области применения искусственного интеллекта: восприятие масштабируемого видеоконтента – что является критически важным для самоуправляемых автомобилей, интерактивных роботов, фильтрации и размещения рекламы. Интеграция глубокого обучения в видеоприложения позволит компаниям создавать умные инновационные сервисы, которые раньше были невозможны.
Новинки поступят в продажу к октябре и ноябре.