Продолжаем собирать информацию о грядущем поколении графических ускорителей NVIDIA Pascal. На данный момент точно известно, что процессоры Pascal будут изготавливаться по 16-нм техпроцессу FinFET на мощностях тайваньской компании TSMC, что обеспечит почти вдвое более высокую плотность транзисторов и уменьшение энергопотребления примерно на 70% относительно актуального 28-нм техпроцесса. Многие аналитики сходятся во мнении, что топовый процессор (предположительно GP100) получит 16-17 миллиардов транзисторов при ориентировочном числе CUDA-ядер в 5000-6000 вместо 8 миллиардов транзисторов и 3000 потоковых ядер у Maxwell GM200. GPU GP100 увидит свет вначале в профессиональных решениях, а массовая обкатка Pascal в сегменте игровых решений начнется с более слабого процессора. Ранее компания NVIDIA поступала так с Kepler, да и с Maxwell в том числе.

Архитектура Pascal предусматривает использование стековой памяти HBM2 на одной подложке с самим чипом. В распоряжении десктопных решений будет до 16 ГБ памяти. В профессиональных картах будут использоваться стеки удвоенной плотности, что позволит задействовать до 32 ГБ. Шина памяти 4096 бит обеспечит пропускную способность до 1,2 Тбайт/сек. При переходе к следующему поколению памяти HBM это значение планируется довести до 2 Тбайт/с, что уже может произойти в семействе подуктов NVIDIA Volta.
Pascal получит продвинутую поддержку смешанных вычислений FP16, FP32, FP64. Если в Maxwell (и последнем GPU Fiji от AMD) акцент смещен в сторону игровой производительности при ограничении возможностей FP64-вычислений, то Pascal значительно нарастил мощь в это направлении. Пиковая производительность при операциях с числами двойном точности достигнет 4 терафлопс, а при операциях одинарной точности 10 терафлопс. При этом в следующем поколении Volta планируется достичь еще более впечатляющего значения в 7 терафлопс в расчетах FP64.
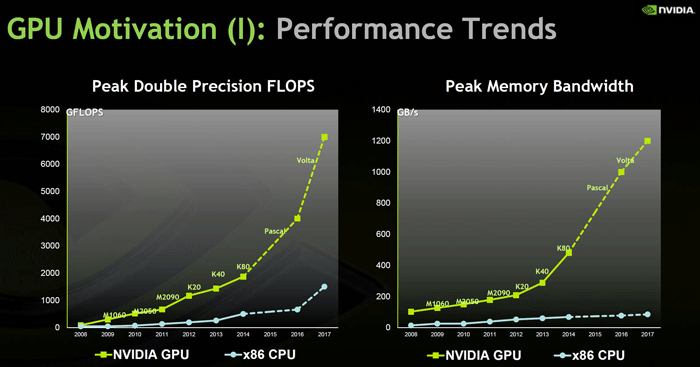
Специализированные решения для высокопроизводительных систем HPC (High Performance Computing) получат поддержку сверхскоростной шины NVLink, которая позволит обмениваться данными в несколько раз быстрее привычного интерфейса PCI Express 3.0. Это расширит возможности применения графических ускорителей в сегменте HPC. Задача крайне важная, ведь по предыдущим графика видно, что рост производительности GPU давно опережает тренд роста производительности процессоров архитектуры x86.

Сами графические решения Pascal получат поддержку разных платформ — x86, ARM и IBM Power.